
Data Engineering Automation: A DataOps Core Practice
Data engineering automation is the application of tools and technologies to streamline data engineering activities. Data engineering automation is a key enabler of DataOps and agile data ways of working (WoW) in general. Data engineering is complicated, requiring great skill and experience. There are many opportunities to apply tooling to improve our efficiency and the quality of our work.
This article is organized into the following sections:
- How data engineering automation fits in
- Data engineering tools
- Data engineering automation in practice
How Data Engineering Automation Fits In
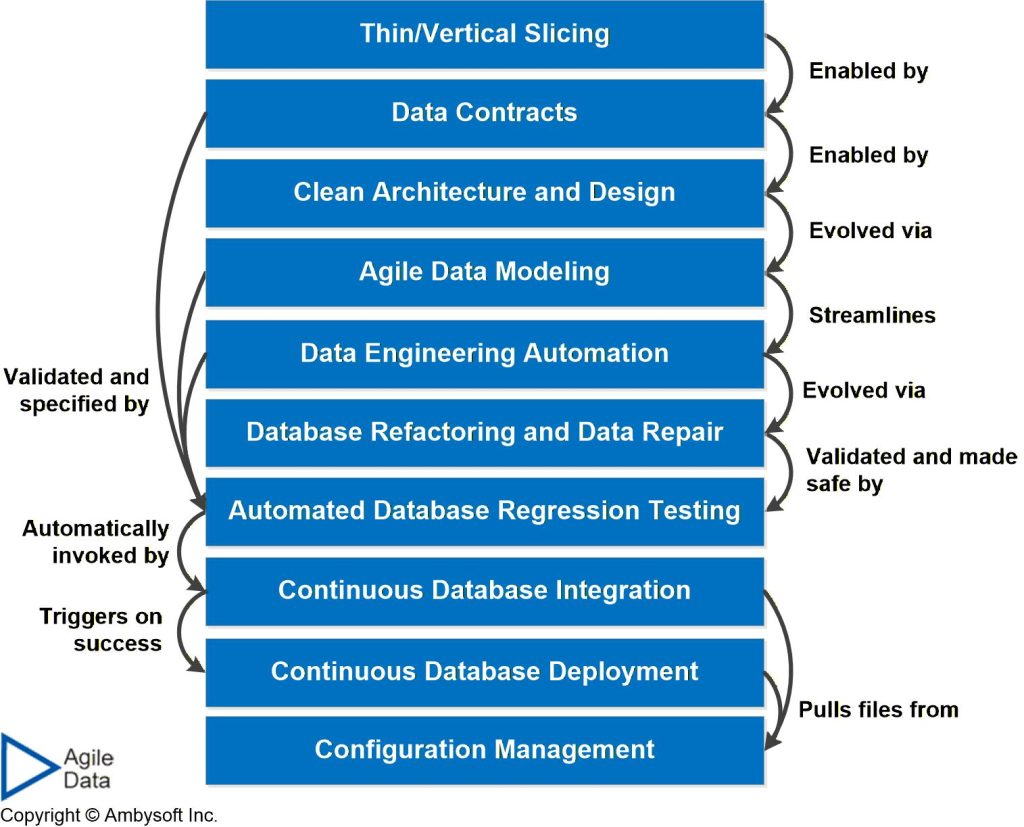
Figure 1 maps common techniques, all of which require tooling support, to the DataOps lifecycle. Figure 2 depicts the agile database techniques stack, showing how common data techniques build upon each other.
Figure 1. The DataOps lifecycle (click to enlarge).

Figure 2. The Agile Database Techniques Stack (click to enlarge).
Data Engineering Tools
Categories of data engineering tooling include:
- Configuration management. All data engineering artifacts should be version-controlled, just as any other software engineering artifact.
- Continuous deployment (CD). Tooling to automatically deploy changes, after successful continuous integration, into the next environment (i.e. from your workstation into your team’s integration sandbox).
- Continuous integration (CI). A CI tool will automatically build your system, run your automated test suite(s), and run any static or dynamic analysis tooling within the current sandbox. Your CI tool is invoked when a change is checked into configuration management.
- Data definition language (DDL) generation. Many tools, particularly data modelling tools, will generate DDL for you. Frankly, I can’t imagine writing DDL by hand anymore.
- Data lineage maintenance. The maintenance of data lineage metadata – required for regulatory compliance, end-user support, and troubleshooting – should be mandatory for any product that generates any form of source-to-target functionality.
- Data load. Tooling that moves data from one data source to another.
- Data manipulation language (DML) generation. Many tools, such as object-to-relational layers (or more generally code-to-data-source layers), will generate the DML code required for basic create-read-update-delete (CRUD) functionality.
- Data profiling. Profiling tools help you to explore the structure and contents of data sources, ideally producing both visual and text representations.
- Data repair. Data repair tools enable you to safely address data quality issues in data sources, potentially even production data sources.
- Data transformation. When it isn’t possible to fix data sources via data repair or database refactoring strategies, you may choose to fix data quality problems via data transformation tools. This tooling is often the “T portion” of extract-transform-load (ETL) or extract-load transform (ELT) tools.
- Database refactoring. A database refactoring is a simple change to the design of your database, such as renaming a column or splitting a column, that improves the quality of the design without changing the semantics in a practical manner. Database refactoring tooling performs the initial refactoring and generates the required scripts to eventually drop the scaffolding code.
- Dynamic analysis. These tools validate that an operational data source works as expected, often focusing on security and performance concerns.
- Source-to-target mapping. These tools map data elements (columns, key attribute pairs, …) in one data source to targets elements in another, often generating the logic required to implement the mapping.
- Static analysis. These tools validate that a data source is designed as expected, often focusing on naming and quality conventions.
- Test automation. Tooling is required to support automated database regression testing.
- Test data management. Tools exist to generate and maintain data required for a range of test types, including load testing, privacy testing, unit testing, and more.
Data Engineering Automation in Practice
I’m a firm believer in adopting and applying great tools on the job. But I’m also keenly aware of the old saying in the IT world: A fool with a tool is still a fool.
The implication is that you must keep qualified people in the loop. You require people with the skills and background to use the tools properly and understand what the tools are doing and why. Beware the promises of tool vendors who claim that their “magical AI tool” can do everything that you need. Maybe they can, but how do you know? How will you maintain and evolve what the tool has done for you, or more pertinently, what the tool has done to you.
Recommended Reading
- Agile Data Tools and Scripts for Better WoW
- Agile Database Techniques Stack The Dev Side of DataOps
- Introduction to DataOps
- Modern Data Engineering Playbook (Thoughtworks)