
Database Refactoring: The Process to Fix Production Databases
A database refactoring is a simple change to a database schema that improves its design while retaining both its behavioural and informational semantics practically. Database refactoring enables you to safely improve the quality of your database schemas, including production database schemas.
The process presented in this article is written from the point of view of a typical production database. When discussing database refactoring, I like to think about it from the point of view of a database that is accessed by 100 different systems, owned by 100 different teams, running on 100 different platforms, and on 100 different release schedules. This is shown in Figure 1. Only one of those systems is the one that my team is responsible for, and the other teams are not under my control. Furthermore, there’s nothing special about the number 100; it could easily be much larger than that. Even in this environment of high coupling, it is still straightforward to successfully implement and deploy database refactorings. And, of course, I am not allowed to break those other applications when I do so.

This article describes how to safely refactor a high-coupled, production database. This is a three-step process:
1. Start In Your Development Sandbox
Your development sandbox is the technical environment where your software, including both your application code and database schema, is developed and unit tested. The need to refactor your database schema is typically identified by an application developer who is trying to implement a new requirement or who is fixing a defect. For example, a developer may need to extend their application to accept Canadian mailing addresses in addition to American addresses. The main difference is that Canadian addresses have postal codes such as R2D 2C3 instead of zip codes such as 90210-1234. Unfortunately the ZipCode column of the SurfaceAddress table is numeric and therefore will not currently support Canadian postal codes. The application developer describes the needed change to one of the Agile data engineer(s) on their team and the database refactoring effort begins.
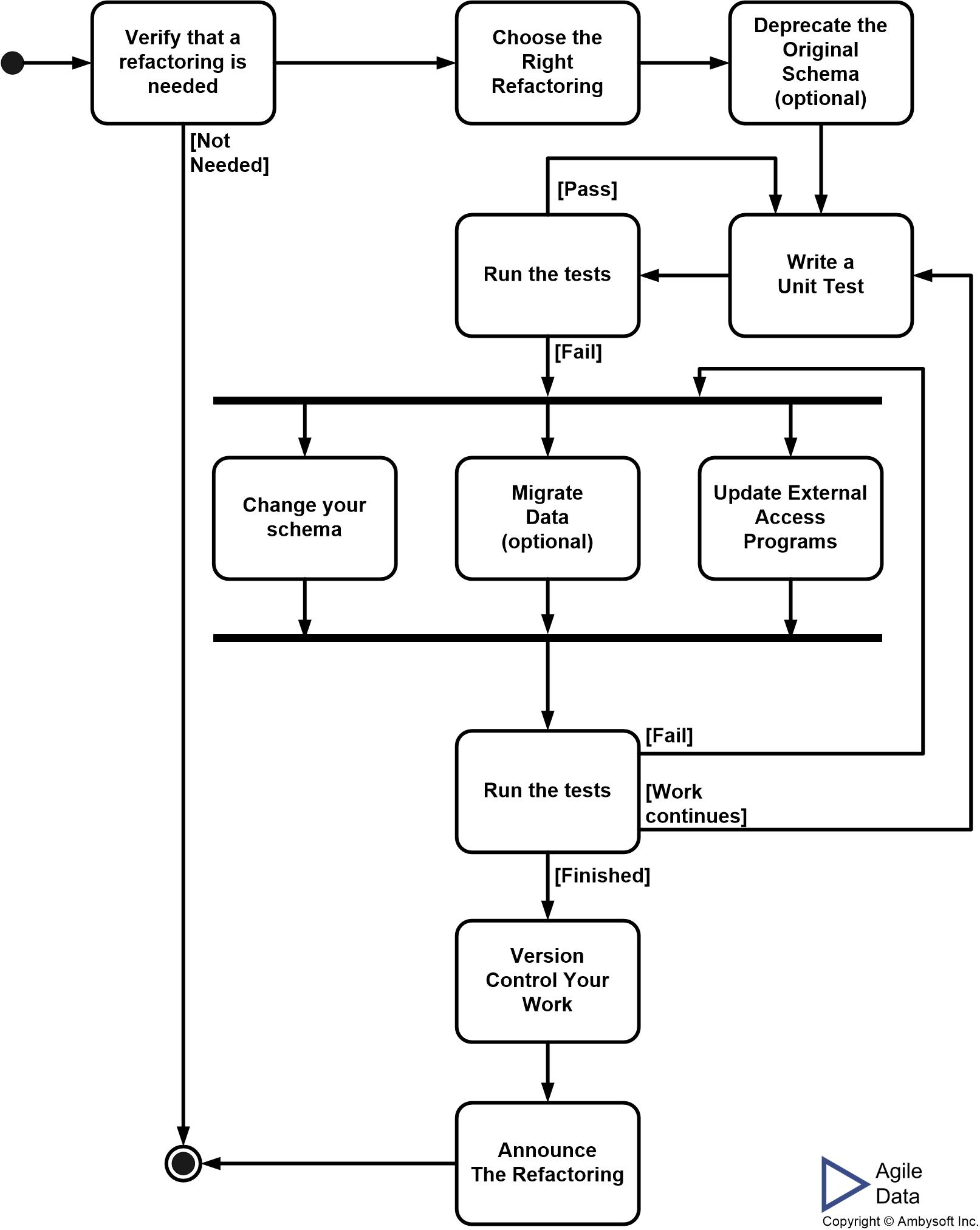
As depicted in Figure 2, the Agile data engineer and application developer will typically work through some or all of the following steps to implement the refactoring:
- Verify that a database refactoring is required
- Choose the most appropriate database refactoring
- Deprecate the original schema
- Write unit tests
- Modify the database schema
- Migrate the source data
- Update external access programs
- Update your data migration script(s)
- Run your regression tests
- Announce the refactoring
- Version control your work
Figure 2. The process of database refactoring.
1.1 Verify that a Database Refactoring is Required
The first thing that the Agile data engineer does is they’ll try to determine if the database refactoring even needs to occur and if it is the right one to perform. The second thing that the Agile data engineer does is internally assess the likeliness that the change is actually needed. This is usually a “gut call” based on the Agile data engineer’s previous experience with the application developer. The next thing the Agile data engineer does is to assess the overall impact of the refactoring.When you are in a simple situation where only one system is coupled to your database, this is fairly straightforward because the Agile data engineer should have an understanding of how the application is coupled to this part of the database. When this isn’t the case they’ll need to work with the application developer to do so.
In the complex case of Figure 1 the Agile data engineer will need to have an understanding of the overall technical infrastructure within your organization and how the other applications are coupled to your database. This is knowledge that they’ll need to build up over time by working with the enterprise architects, agile developers, and even other Agile data engineers. When the Agile data engineer isn’t sure of the impact they will either need to decide to make a decision at the time and go with their gut feel or decide to advise the application developer to wait while they talk to the right people. The goal of this effort is to make sure that you attempt a database refactoring that you aren’t likely going to be able to do – if you are going to need to update, test, and redeploy twenty other applications to make this refactoring then it likely isn’t viable for you to continue.
1.2 Choose The Most Appropriate Database Refactoring
An important skill that Agile data engineers require is the understanding that you typically have several choices for implementing new data structures and new logic within a database.
1.3 Write Your Unit Tests
Like code refactoring, database refactoring is enabled by the existence of a comprehensive test suite – you know you can safely change your database schema if you can easily validate that the database still works after the change. Here’s my advice:
- Your primary goal is to ensure that the tests exist.
- You should try to have each test implemented once, either at the application level or at the database level but not both.
- Some unit tests will be at the application level and some at the database level, and that’s ok.
- Go for the lowest common denominator – if the database is accessed by several applications thed any data-related tests should appear in your database test suite, helping to ensure they’re tested once.
- When you have a choice, implement the test at the level where you have the best testing tools (often at the application level). Testing tools are discussed in the Tools article.
The article Database Regression Testing describes database testing in detail.
1.4 Deprecate The Original Schema
An effective technique that Pramod Sadalage and Peter Schuh (2002) promote is a deprecation period, although transition period is a better term, for the original portion of the schema that you’re changing. They observe that you can’t simply make the change to your database schema instantly, that instead you need to work with both the old and the new schema in parallel for awhile to provide time for the other application teams to refactor and redeploy their systems.
Figure 3 shows how this idea would work when we apply the Replace Column database refactoring to CustomerNumber (this example was created in 2023, hence a removal date in 2027 – more on this later). Notice the changes between the original schema and the schema during the transition period. Customer.CustomerID has been added as a column, exactly what you would expect. The CustomerNumber \column has been marked as deprecated – you know this because a removal date has been assigned to it using a UML named variable. A trigger was also introduced to keep the values contained in the two columns synchronized, the assumption being that new application code will work with CustomerNumber but should not be expect to keep CustomerID up to date, and that older application code that has not been refactored to use the new schema won’t know to keep CustomerID up to date. This trigger is an example of database scaffolding code, simple and common code that is required to keep your database “glued together”. This code has been assigned the same removal date as CustomerNumber.
Figure 3. Applying Replace Column to improve the Customer table (click to enlarge).

To see how to implement the code for a database refactoring, read The Rename Column Database Refactoring.
Figure 4 depicts the lifecycle of a database refactoring. You first implement it within the scope of your initiative, and if successful you eventually deploy it into production. During the transition period both the original schema and the new schema exist, with sufficient scaffolding code to ensure that any updates are correctly supported. During the transition period some applications will work with PostCode and others with ZipCode, but not both at once. Regardless of which column they work with, the applications should all run properly. Once the deprecation period has expired the original schema plus any scaffolding code is removed and the database retested. At this point in time the assumption is that all applications work with PostCode.
Figure 4. The lifecycle of a database refactoring. (click to enlarge)

- Coordinate. Implement the refactoring, coordinating with the appropriate people at the organizational level (likely your data management group) to ensure it gets into your overall change process.
- Collaborate. Teams across your organization work together to change anyhing coupled to the database (see Figure 1).
- Conclude. The original schema and scaffolding code are removed, effectively concluding the refactoring.
1.5 Modify the Database Schema
The application developer and Agile data engineer work together to make the changes within the development sandbox. The strategy is to start each refactoring simply, by performing the refactoring within the development sandbox first you are effectively putting yourself in the situation of only one system (yours) coupled to the database.
To do this, you need to update two logs (assuming you don’t have a database refactoring tool which does this automatically):
- Database change log. This is the source code implementing all database schema changes in the order that they were applied throughout the course of an initiative. When you are implementing a database refactoring, you include only the immediate changes in this log. When applying the Replace Column database refactoring we would include the DDL for adding the PostCode column and the data definition language (DDL) to implement the trigger(s) to maintain the values between the PostCode and ZipCode columns during the transition period.
- Update log. This log contains the source code for future changes to the database schema that are to be run after the transition period for database refactorings. In our example this would be the source code required to remove the ZipCode column and the triggers we introduced.
1.6 Migrate the Data
Many refactorings require you to migrate, or copy data, from the old version of the schema to the new. Your data migration log contains the data manipulation language (DML) to reformat or cleanse the source data throughout the course of your effort. In our example this would include any code to improve the quality of the values in the ZipCode column.
1.7 Update External Programs
The programs which access the portion of the database schema which you’re refactoring must be updated to work with the new version of the database schema. All of these programs must be refactored and then deployed in production before the transition period expires, as implied in Figure 4.
1.8 Run Your Regression Tests
Once the changes to your application code and database schema have been put in place you then need to run your regression test suite. Because successful tests discover problems you will need to rework things until you get it right. A significant advantage of database refactorings being small changes is that if your tests do in fact break you’ve got a pretty good idea where the problem lies – in the application code and database schema that you just changed. The larger your changes are the more difficult it becomes to track down problems, and therefore the slower and less effective your development efforts are. You’ll discover that developing in small, incremental steps works incredibly well in practice.
1.9 Announce the Database Refactoring
Because your database is a shared resource, minimally it is shared within your application development team if not by several application teams, the Agile data engineer needs to communicate the changes that have been made. If you haven’t already done so you should update the physical data model (PDM) for your database. I personally have a tendency to model the new schema in a PDM tool such as ERWin and then generate the initial DDL that I’ll then modify and include in my database change scripts.
1.10 Version Control Your Work
A critical skill for agile developers is the habit of putting all of their work under configuration management (CM) control by checking it into a version control tool. In the case of database refactoring this includes any DDL that you’ve created, change scripts, data migration scripts, test data, test cases, test data generation code, documentation, and models. This is in addition to the application-oriented artifacts that you would normally version – treat your database-oriented artifact the exact same way that you’d treat other development artifacts and you should be ok.
2. Implement The Database Refactoring In Your Integration Sandbox
After several days have passed you will be ready to implement your database refactoring within your team integration sandbox. The reason why you need to wait to do so is to give your teammates time to refactor their own code to use the new schema.
Teams that have chosen to encapsulate access to their database via the use of a persistence framework will find it easier to react to database schema changes and therefore may discover they can tighten up the period between implementing a database refactoring within a development sandbox and in their team integration sandbox. This is due to the fact that the database schema is represented in meta data, therefore many database schema changes will only require updates to the meta data and not to the actual source code.
To deploy into each sandbox you will need to both build your application and run your database management scripts (tools such as Autopatch can help). The next step is to rerun your regression tests to ensure that your system still works – if not you will need to fix it in your development environment, redeploy, and retest. The goal in your team integration sandbox is to validate that the work of everyone on your team functions when put together, whereas your goal in the Test/QA sandbox is to validate that your system works well with the other systems within your organization.
Communication is a critical part of deploying database refactorings into your Test/QA sandbox, I’m using the plural now because you typically introduce several database changes (refactorings) into this environment at once. Long before you change your database schema you need to communicate and negotiate the changes with the owners of all of the other applications that access your database. Your operations engineers (if any) will be involved in this negotiation, they may even facilitate the effort, to ensure that the overall needs of your organization are met. Luckily the process that you followed in your development sandbox has made this aspect of database refactoring easier:
- The Agile data engineer only allowed database refactorings that can realistically be implemented – if another application team isn’t going to be able to rework their code to access the new schema then you can’t make the change.
- The documentation, even if it’s only a brief description of each change, that the Agile data engineer wrote is important because it provides an overview of the changes that are about to be deployed.
- The new version physical data model (PDM), which was updated as database refactorings were implemented, serves as a focal point for the negotiations with other teams. Agile Modeling (AM) would consider the PDM to be a “contract model” that your team has with the other application teams, a model that they can count on to be accurate and that they can count on being actively involved in negotiating changes to it.
3. Install The Database Refactoring Into Production
Installing into production is the hardest part of database refactoring, particularly in the complex situation of Figure 1. You generally won’t deploy database refactorings on their own, instead you will deploy them as part of the overall deployment of one or more systems. Deployment is easiest when you have one application and one database to update, and this situation does occur in practice, but realistically we need to consider the situation where you are deploying several systems and several data sources at once. Figure 5 overviews the steps of deploying your refactorings into production.
Figure 5. The steps of deploying your database refactorings (click to enlarge).

Figure 6 depicts how you will need to schedule the deployment of your application pre-defined deployment windows, shown in green. A deployment window, often called a release window, is a specific point in time where it is permissible to deploy a system into production. Your operations staff will very likely have strict rules regarding when application teams may deploy systems. Figure 6 shows how two teams schedule the deployment of their changes (including database refactorings) into available deployment windows. Sometimes there is nothing to deploy, sometimes one team has changes, and other times both teams have schema changes to deploy.
Figure 6. Scheduling your refactorings into deployment windows (click to enlarge).

You will naturally need to coordinate with any other teams which are deploying during the same deployment window. This coordination will occur long before you go to deploy, and frankly the primary reason why your pre-production test environment exists is to provide a sandbox in which you can resolve multi-system issues. Regardless of how many database refactorings are to be applied to your production database, or how many teams those refactorings were developed by, they will have first been tested within your pre-production testing environment before being applied in production.
4. Parting Thoughts
This article is written under the assumption that your technical and cultural environments are organized to support database refactoring. This sounds like a big assumption because it is. I describe what you need to do to get to the point where these environments are in fact in place. Anything less would be inappropriate.