
Database Testing: Automated Database Regression Testing
Automated database regression testing is the act of running a test suite regularly. Ideally, your database testing suite is automatically invoked whenever a developer or data engineer has done something which could potentially inject a defect into the implementation of a database.
This article works through the following topics:
- The logic of an automated database test
- Writing a database test
- Supporting automated database testing
- Database testing tools
- Automated database testing in context
- Related Resources
1. The Logic of an Automated Database Test
The goal of an automated regression test is that you want it to validate that something of value is correct. In the case of a database method, such as a stored function in a relational database, that it does what you expect it to do. In the case of a data value, or collection of values, that the values are what you expect them to be.
The logical steps of a single database test are:
- Start a transaction. All database tests should be run as a transaction so as to avoid side effects. More on this later.
- Load specific data required for the test (if any). As with any type of test, you must start it in a known state.
- Run the test.
- Check the results. Is the new state of the database what you expect?
- Rollback the transaction. This ensures there are no side effects to the database from running the test.
2. Writing a Database Test
There’s no magic when it comes to writing a database test, you write them just like you would any other type of test. Writing each individual database test is typically a four-step process:
2.1 Identify What You Want to Test
Figure 1 indicates what you should consider testing regarding databases. The diagram is drawn from the point of view of a single database, the dashed lines indicate threat boundaries, indicating that you need to consider threats both within the database (internal testing) and at the interface to the database (interface/black box testing). The point is that there is a lot of important data and supporting functionality that we should validate on a regular basis.
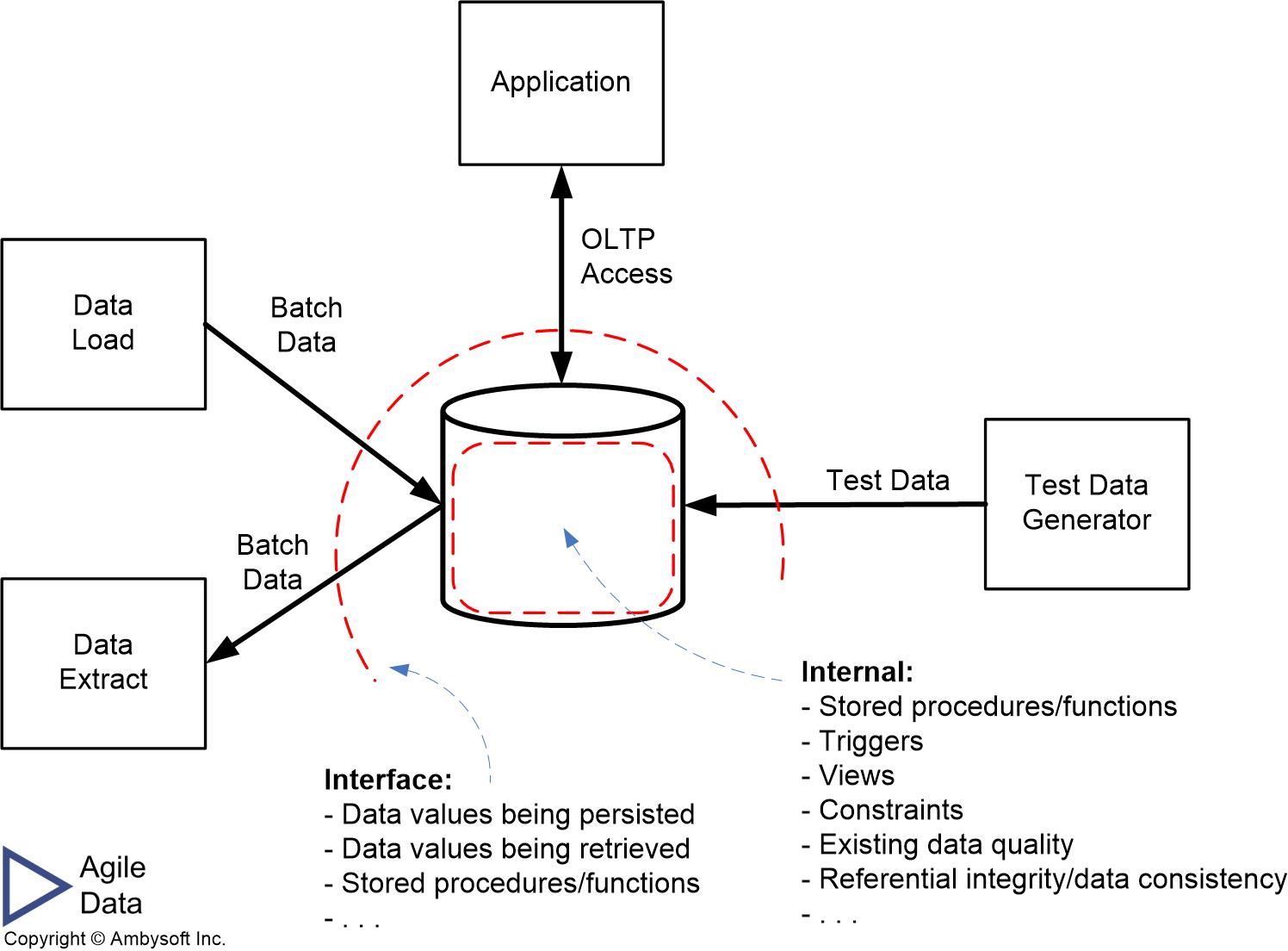
Part of identifying what you want to test is to identify the scope of the test. Potential levels of scope include:
- A business requirement. Depending on your modeling approach, this may be defined for you already in the form of an acceptance test specification. Acceptance tests are often identified to capture the details behind usage requirements, such as use cases or question stories. If this isn’t the case, you’re effectively writing an acceptance test on a just-in-time (JIT) basis, or perhaps even a behaviour-driven development (BDD) basis.
- An aspect of your design. Figure 1 provides some insight for us, particularly the list of internal features. Perhaps we want to validate a method, such as a stored procedure. Or we may write a test that validates that expected structures, such as views and tables, exist.
- A quality of service (QoS) requirement. Q0S requirements, such as a security or performance constraint, define critical aspects that cross-cut business requirements. Similar to functional requirements they should also be validated.
For a more detailed discussion, read the article What To Test in a Database.
A similar issue is the type of the test is also an important consideration. I like to think in terms of three fundamental types:
- Unit test. A unit test validates a specific, and often small, amount of value. You may have a unit test that checks the value of a stored function, or one that validates that a data field conforms to a data invariant.
- Internal integration test. This type of test validates that value involving several units (such as database methods, data fields, or data structures) works as expected. For example, you may want to test that a cascading delete, say the deletion of an Order record and its corresponding OrderItem records, works.
- External integration test. This type of test validates that an external system was interacting with the database as expected. For example, does the data extract shown in Figure 1 works as expected? Integration tests such as this are often the domain of the external system, not of the database. Or perhaps it’s a shared responsibility. Regardless, this is a test strategy decision that your organization needs to make.
Regarding types, there’s no hard and fast rules as to the exact type. Instead it depends on your context. For example, consider a test that validates the calculation logic in a view that combines data from multiple data structures (say tables in a relational database). Is this a unit test because you’re validating a single view? Or is it an internal integration test because data from multiple structures are involved. Bottom line is that it doesn’t really matter how you label the test, if you’re doing so at all. What really matters is that the test is adding value to your overall regression test suite.
2.2 Setup the Database Test
Just like any other type of test, you need to first put your environment into a known state. In this case the environment is the portion of the database that your test validates. To do so, a database test may need to load some test data before the test is run.
2.3 Run the Database Test
As noted earlier, the overall test code is wrapped by a transaction. This is because database testing is fundamentally different than simple application testing in that database tests are potentially coupled via the database itself. Let’s walk through several scenarios to understand how database tests can be coupled to one another:
- A database test doesn’t return the database to the state that it found itself in. For example, an automated test checks a database method that makes a deposit into a bank account. The test deposits $20 into an account containing $100, checks to see if the account balance was updated by $20, but doesn’t remove the $20 afterwards. Another test expects the balance to be $100 and unfortunately doesn’t check to see if that’s true. The test then attempts a $110 withdrawal against the account expecting that it wouldn’t work because of insufficient funds. The withdrawal works, resulting in a new balance of $10 and a broken test. The two tests are inadvertently coupled due to poor coding of both.
- Several database tests are purposefully run in order. If you put the database into a known state, then run several tests against that known state before resetting it, then those tests are potentially coupled to one another. Coupling between tests occurs when one test counts on another one to successfully run so as to put the database into a known state for it. This becomes problematic if one of the subtests are dropped or the tests reordered.
- Several database tests are run in parallel but not as transactions. For example, three developers are running tests against the database in their team integration sandbox at the same time. None of the tests are written as transactions. If two or more tests update the same data field in parallel to one another one or more of these tests are going to fail. This is effectively a database collision caused by the running tests.
My recommendation, which I made above, is to run each database test as a separate transaction which is then rolled back as the final step. Yes, this will prove to be a bit slower due to the overhead of transaction control and the need for individual setup steps.
2.4 Check the Results
Once a test is run you need to check the results to verify that what you expected to happen actually happened. Once again, because you’re working with a database this can be a bit harder than if you’re just testing application code. For example, you have a unit test that validates that a method performing a calculation works properly. Minimally you’ll need to check that the method returns the value that you expect, just like you would testing application logic. However, if that calculated value, and potentially values from interim steps of the calculation, are meant to be stored then you need to check whether those updates actually happened.
3. Supporting Automated Database Testing
There are several strategies that you should adopt to support automated database regression testing. These strategies are:
3.1 Test Data Management
An important part of writing database tests is the creation of test data. You have several strategies for doing so:
- Have source test data. You can maintain an external definition of the test data, perhaps in flat files, XML files, or a secondary set of tables. This data would be loaded in from the external source as needed.
- Test data creation scripts. You develop and maintain scripts, perhaps using data manipulation language (DML) SQL code or simply application source code (e.g. Java or C#), which does the necessary deletions, insertions, and/or updates required to create the test data.
- Self-contained test cases. Each individual test case puts the database into a known state required for the test.
These approaches to creating test data can be used alone or in combination. A significant advantage of writing creation scripts and self-contained test cases is that it is much more likely that the developers of that code will place it under configuration management (CM) control . Although it is possible to put test data itself under CM control, worst case you generate an export file that you check in. My advice is to put all valuable assets, including test data, under CM control.
Where does test data come from? For unit testing, I prefer to create sample data with known values. This way I can predict the actual results for the tests that I do write and I know I have the appropriate data values for those tests. For other forms of testing – particularly load/stress, system integration, and function testing, I will use live data so as to better simulate real-world conditions.
3.2 Database Sandboxes

3.3 Continuous Database Integration (CDI)
Continuous database integration (CDI) is the automatic invocation of the build process for a database. The idea is that whenever something changes that affects the implementation of your database, such as an update to the schema definition or an update to method code, the build process is automatically invoked. This is depicted in Figure 3. As you can see, this includes automatically invoking the regression test suite for your database.
Figure 3. The process of continuous database integration (CDI).
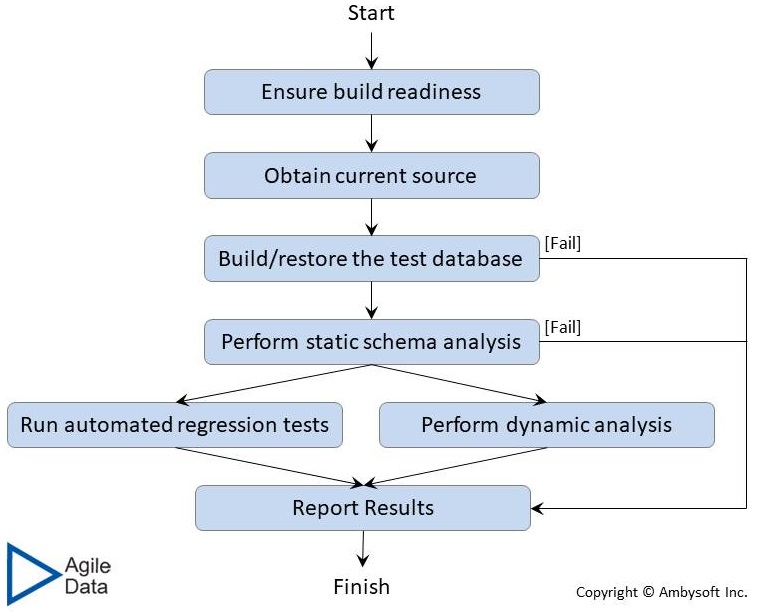
To successfully test your database you must first know the exact state of the database, and the best way to do that is to simply put the database in a known state before running your test suite. This is captured by the Build/restore the test database step in Figure 3. There are two common strategies for doing this:
- Fresh start. A common practice is to rebuild the database, including both creation of the schema as well as loading of initial test data, for every major test run (e.g. testing that you do in your team integration or pre-production test sandboxes).
- Data reinitialization. For testing in developer sandboxes, something that you should do every time you rebuild the system, you may want to forgo dropping and rebuilding the database in favor of simply reinitializing the source data. You can do this either by erasing all existing data and then inserting the initial data vales back into the database, or you can simply run updates to reset the data values. The first approach is less risky and may even be faster for large amounts of data.
4. Database Testing Tools
I believe that there are several critical features which you need to successfully test databases. First, as Figure 1 implies you need two categories of database testing tools, one for interface tests and one for internal database tests. Second, these testing tools should support the language that you’re developing in. For example, for internal database testing if you’re a Microsoft SQL Server developer, your Transact-SQL (T-SQL) procedures should likely be tested using some form of T-SQL framework. Similarly, Oracle DBAs should have a PL-SQL-based unit testing framework. Third, you need tools which help you to put your database into a known state, which implies the need not only for test data generation but also for managing that data (like other critical development assets, test data should be under configuration management control).
To make a long story short, although we’re starting to see a glimmer of hope when it comes to database testing tools, as you can see in Table 1, but we still have a long way to go. Luckily there are some good tools being developed by the open source software (OSS) community and there are some commercial tools available as well. Having said that, IMHO there is still significant opportunity for tool vendors to improve their database testing offerings.
Table 1. Some database testing tools.
| Category | Description | Examples* |
| Testing tools for load testing | Tools simulate high usage loads on your database, enabling you to determine whether your system’s architecture will stand up to your true production needs. | |
| Test Data Generator | Developers need test data against which to validate their systems. Test data generators can be particularly useful when you need large amounts of data, perhaps for stress and load testing. | |
| Test Data Management | Your test data needs to be managed. It should be defined, either manually or automatically (or both), and then maintained under version control. You need to define expected results of tests and then automatically compare that with the actual results. You may even want to retain the results of previous test runs (perhaps due to regulatory compliance concerns). | |
| Unit testing tools | Tools which enable you to regression test your database. |
|
* = Inclusion in this list does not imply any sort of recommendation for any of the products.
5. Automated Database Testing in Context
The following table summarizes the trade-offs associated with automated database testing and provides advice for when (not) to adopt it.
| Advantages |
|
| Disadvantages |
|
| When to Adopt This Practice | Any data source that is considered an enterprise asset should have an automated regression test suite. Otherwise it isn’t really an asset, is it? |
6. Related Resources
- The Agile Database Techniques Stack
- An Introduction to Database Testing
- Clean Database Design
- Continuous Database Integration (CDI)
- Data Debt: Understanding Enterprise Data Quality Problems
- Database Testing Terminology: A Glossary of Terms
- Introduction to DataOps: Bringing Databases Into DevOps
- Introduction to Test-Driven Development (TDD)
- What To Test in a Database