
Database Refactoring: Fix Production Data Quality Problems at the Source
Table of Contents
- Refactoring
- Database Refactoring
- Why Database Refactoring is Hard
- How to Refactor Your Database
- Adopting Database Refactoring Within Your Organization
- Strategies for Database Refactoring
- Database Refactoring and Data Repair
- Database Refactoring in Context
- Parting Thoughts
1. Refactoring
Martin Fowler (1999) describes a programming technique called refactoring, a disciplined way to restructure code. The basic idea is that you make small changes to your code to improve your design, making it easier to understand and to modify. Refactoring enables you to evolve your code slowly over time, to take an iterative and incremental approach to programming. Martin’s refactoring site, Refactoring.com, is a good online resource.
A critical aspect of a refactoring is that it retains the behavioral semantics of your code, at least from a black box point of view. For example there is a very simple refactoring called Rename Method, perhaps from getPersons() to getPeople(). Although this change looks easy on the surface you need to do more than just make this single change, you must also change every single invocation of this operation throughout all of your application code to invoke the new name. Once you’ve made these changes then you can say you’ve truly refactored your code because it still works again as before.
It is important to understand that you do not add functionality when you are refactoring. When you refactor you improve existing code, when you add functionality you are adding new code. Yes, you may need to refactor your existing code before you can add new functionality. Yes, you may discover later on that you need to refactor the new code that you just added. The point to be made is that refactoring and adding new functionality are two different but complementary tasks.
2. Database Refactoring
In the February 2002 issue of Software Development I described a technique that I called data refactoring. This article described my preliminary experiences at something that should more appropriately have been called database refactoring in hindsight. Hence the new name. From this point forward I’ll use the term code refactoring to refer to traditional refactoring as described by Fowler to distinguish it from database refactoring.
Let’s start with some definitions. A database refactoring is a simple change to a database schema that improves its design while retaining both its behavioral and informational semantics in a practical manner. For the sake of this discussion a database schema includes both structural aspects such as table and view definitions as well as functional aspects such as stored procedures and triggers. An interesting thing to note is that a database refactoring is conceptually more difficult than a code refactoring; code refactorings only need to maintain behavioral semantics while database refactorings also must maintain informational semantics.
There is a database refactoring named Split Column, one of many described in A Catalog of Database Refactorings, where you replace a single table column with two or more other columns. For example you are working on the Person table in your database and discover that the FirstDate column is being used for two distinct purposes – when the person is a customer this column stores their birth date and when the person is an employee it stores their hire date. Your application now needs to support people who can be both a customer and an employee so you’ve got a problem. Before you can implement this new requirement you need to fix your database schema by replacing the FirstDate column with BirthDate and HireDate columns. To maintain the behavioral semantics of your database schema you need to update all source code that accesses the FirstDate column to now work with the two new columns. To maintain the informational semantics you will need to write a migration script that loops through the table, determines the type, then copies the existing date into the appropriate column. Although this sounds easy, and sometimes it is, my experience is that database refactoring is incredibly difficult in practice when cultural issues are taken into account (more on this later).
2.1 Why Database Refactoring?
Agile methodologies such as Scrum, Extreme Programming (XP), and SAFe take an iterative and incremental approach to software development. Application developers on agile teams typically forsake big design up front (BDUF) approaches in favour of emergent approaches where the design of a system evolves throughout the life of the initiative. On an agile development initiative the final design often isn’t known until the application is ready to be released. This is a very different way to work for many experienced IT professionals.
The implication is that the traditional approach of creating a (nearly) complete set of logical and physical data models up front isn’t going to work. The main advantage of the traditional approach is that it makes the job of the data engineer much easier – the data schema is put into place early and that’s what people use. However there are several disadvantages. First, it requires the designers to get it right early, forcing you to identify most requirements even earlier in the initiative, and therefore forcing your team into taking a serial approach to development. Second, it doesn’t support change easily. As things progress your stakeholders understanding of what they need will evolve, motivating them to evolve their requirements. The business environment will also change during your effort, once again motivating your stakeholders to evolve their requirements. In short the traditional way of working simply doesn’t work well in an agile environment. If agile data engineers are going to work on and support teams that are following agile methodologies they need to find techniques that support working iteratively and incrementally. My experience is that one critical technique is database refactoring.
There are three fundamental reasons why you should be interested in database refactoring:
- To safely fix existing legacy databases. The bottom line is that legacy databases aren’t going to fix themselves, and that from a technical point of view database refactoring is a safe, simple way to improve data, and database, quality over time. My various surveys into data quality have consistently shown over the years that organizations suffer from data quality issues but in many cases do not have a realistic strategy in place to address them.
- To support evolutionary development. Modern software development processes, such as SAFe, XP, and Scrum, all work in an evolutionary manner. Data professionals need to adopt techniques, including this one, which enable them to work in such a manner.
- To tune your database.. Part of your tuning efforts may include the (de)normalization of the schema.
2.2 Preserving Semantics
Informational semantics refers to the meaning of the information within the database from the point of view of the users of that information. To preserve the informational semantics implies that when you change the values of the data stored in a column the clients of that information shouldn’t be affected by the improvement. Similarly, with respect to behavioral semantics the goal is to keep the black box functionality the same – any source code that works with the changed aspects of your database schema must be reworked to accomplish the same functionality as before.
2.3 What Database Refactorings Aren’t
A small transformation to your schema to extend it, such as the addition of a new column or table, is not a database refactoring because the change extends your design. A large number of small changes simultaneously applied to your database schema, such as the renaming of ten columns, would not be considered a database refactoring because this isn’t a single, small change. Database refactorings are small changes to your database schema that improve its design while preserving the behavioral and informational semantics. That’s it. I have no doubt that you can make those changes to your schema, and you may even follow a similar process, but they’re not database refactorings.
3. Why Database Refactoring is Hard
Coupling. Coupling is a measure of the degree of dependence between two items – the more highly coupled two things are the greater the chance that a change in one will require a change in another. Coupling is the “root of all evil” when in comes to database refactoring, the more things that your database schema is coupled to the harder it is to refactor. Databases are potentially coupled to a wide variety of things:
- Your application source code
- Other application source code
- Data load source code
- Data extract source code
- Database encapsulation/persistence frameworks
- Your database schema (captured via models or scripts)
- Data migration scripts
- Test code
- Models and/or documentation
Figure 1 depicts the best-case scenario for database refactoring – when it is only your application code that is coupled to your database schema. Then Figure 2 depicts the worst-case scenario for database refactoring efforts where a wide variety of software systems are coupled to your database schema, a situation that is quite common with existing production databases.
Figure 1. The best-case scenario.

Figure 2. The worst-case scenario (click to enlarge).

As you can see, coupling is a serious problem when it comes to database refactoring. For the sake of simplicity, throughout the rest of this article the term “client system” will refer to all external systems, databases, applications, programs, test suites ” that are coupled to your database.
4. The Process of Database Refactoring
Before I describe the steps for refactoring a database I need to address a critical issue – Does the simple situation depicted in Figure 1 imply you’ll do different things than the highly coupled one of Figure 2? Yes and no. The fundamental process itself remains the same although the difficulty of implementing individual database refactorings increases dramatically as the coupling your database is involved with increases. If you find yourself in the simple situation then you will not need to do the transition period work described below, you can simply refactor your database schema and application code in parallel and deploy them simultaneously. People who find themselves in the more complex situation do not have this luxury.
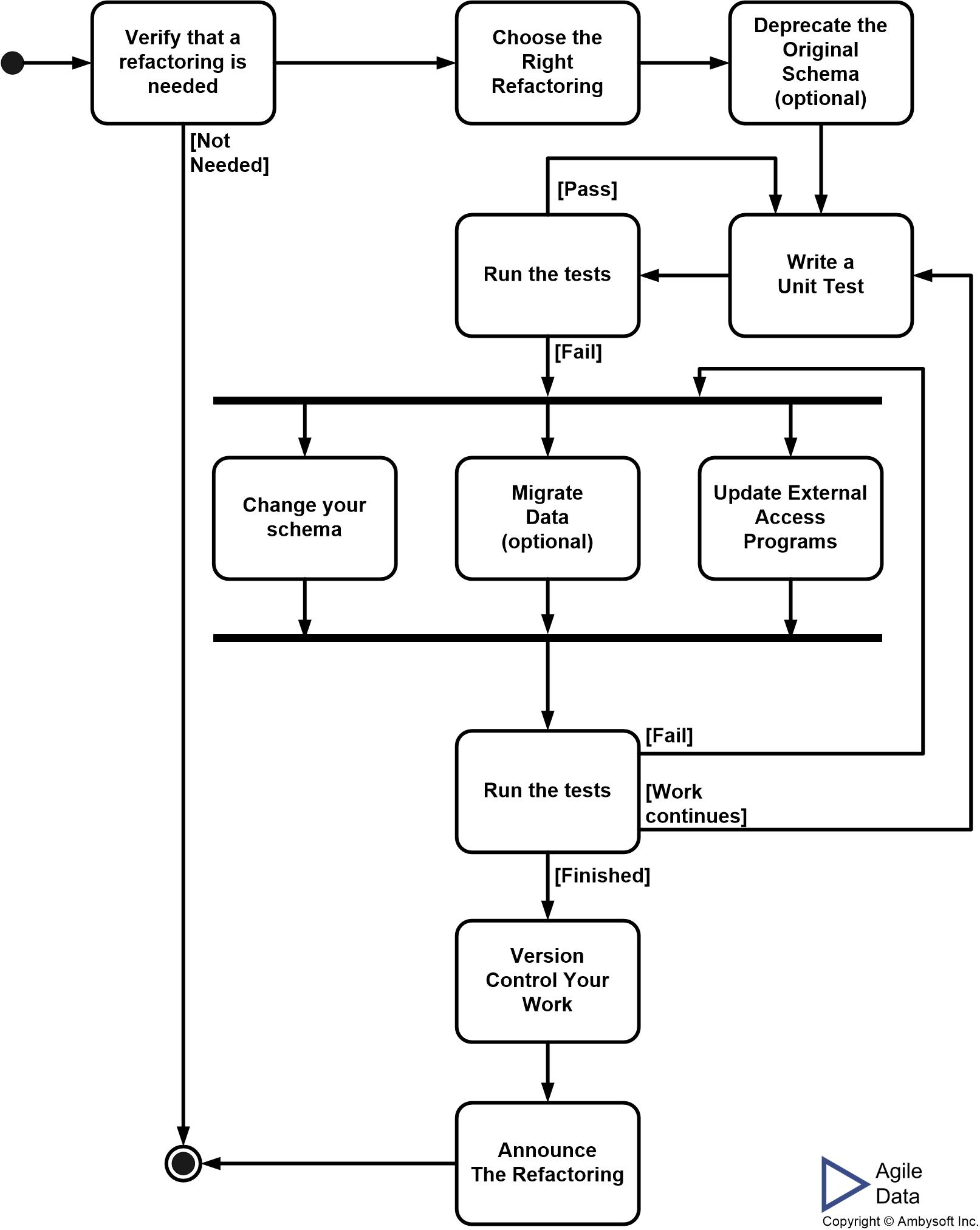
As shown in Figure 3, the Agile data engineer and application developer will typically work through some or all of the depicted steps to implement the refactoring. You generally won’t deploy database refactorings on their own, instead you will deploy them as part of the overall deployment of one or more systems. Deployment is easiest when you have one application and one database to update, and this situation does occur in practice, but realistically we need to consider the situation where you are deploying several systems and several data sources at once. Figure 4 overviews the steps of deploying your refactorings into production. The detailed process of database refactoring is described in the article Database Refactoring: The Process to Fix Production Databases.
Figure 3. The process to implement a database refactoring.

5. Adopting Database Refactoring Within Your Organization
Although the adoption of effective tools is an important part of enabling database refactoring it is only the tip of the iceberg – database refactoring requires a significant cultural change within your organization. Many of the cultural issues for adopting database refactoring are the same ones that you face adopting the Agile Data method in general. These cultural issues include a serial/traditional mindset within many data professionals, resistance to change, and political inertia. The following approach should help you to overcome these challenges:
- Start simple. Refactoring databases is easiest in greenfield environments where a new application accesses a new database, and the next easiest situation is when a single application accesses a legacy database. Both of these scenarios are typified by Figure 1. By starting simple you provide yourself with an environment in which you can learn the basics, once you understand the basics you are in a much better position to tackle the situations typified by Figure 2.
- Accept that iterative and incremental development is the norm. Modern software development methodologies take an iterative and incremental approach to software development. Although serial development is often the preferred approach by many data professionals unfortunately it doesn’t reflect the quickly changing .
- Accept that there is no magic solution to get you out of your existing mess. Your data quality problems didn’t create themselves and they are not going to fix themselves. People created the problem and people need to fix the problem. Database refactoring is the safest and most straightforward strategy available to you to dig your way out of your data technical debt.
- Adopt a 100% database regression testing policy. For database refactoring to work, and in general for iteratively and incremental development to work, you need to be effective at database regression testing. To be successful, you need to not only be able to regression test the database itself but any application that is coupled to your database. The implication is that you require regression test suites for every single application, something you very likely do not have. So start writing them.
- Explore the technique. Experiment with database refactoring in simple situations first to learn the technique and gain some experience. Then start refactoring more complicated things. So, start simple.
For many organizations database refactoring is a new, “bleeding edge” technique. The good news is that it has been proven in practice, and is well-documented in the book Refactoring Databases.
6. Strategies for Database Refactoring
In Refactoring, Martin Fowler suggests a collection of practices for code refactoring. These practices are recast for database refactoring:
- Refactor to ease additions to your schema.
- Ensure the database regression test suite is in place.
- Take small steps.
- Build for people.
- Don’t publish data models prematurely.
- The need to document reflects a need to refactor.
- Test frequently.
7. Database Refactoring and Data Repair
In the past Data Quality Refactorings were in effect data repairs. The problem was that many of them changed the semantics of the persistent data, and refactorings are not supposed to change the semantics. As a result in 2023 I decided to refactor data repair out of the database refactoring practice. By teasing the DQ refactorings out into the data repair practice we achieve the following benefits:
- The importance of data repair is made clear. Repairing data quality problems at the source should be, and is, a named practice.
- Database refactoring becomes “pure”. A refactoring, of your database or otherwise, is a change that improves the design without changing its semantics. Many data repairs, by their very definition, change the semantics. The remaining 50+ database refactorings do not change the semantics.
8. Database Refactoring in Context
The following table summarizes the trade-offs associated with database refactoring and provides advice for when (not) to adopt it.
| Advantages |
|
| Disadvantages |
|
| When to Adopt This Practice | You need to have a reasonably complete automated regression test suite in place, one that at least validates the critical and high-risk aspects of your database, for database refactoring to be a viable option. |
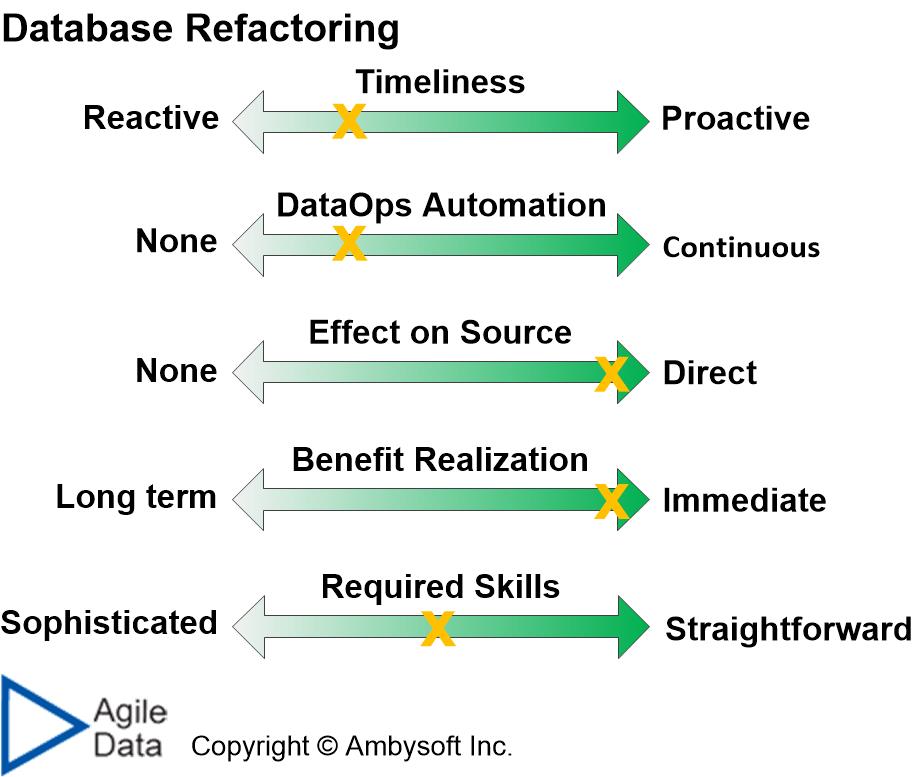
Figure 5 depicts the data quality technique comparison factor ratings for database refactoring. The reasonings for each factor score are:
- Timeliness. Database refactoring tends to be a mostly reactive activity – you run into a data quality problem, something that may have been there for years, and you decide to fix it.
- Level of automation. Although there is tooling to help you with database refactoring, this tooling is typically used at the time that the refactoring is performed. The database refactoring is an event, it isn’t logic that is added into your DataOps automation strategy.
- Effect on source. Database refactoring directly fixes the source data.
- Benefit realization. You see immediate benefit from fixing the data quality problem.
- Required skills. Database refactoring is something that can be taught to data professionals relatively easily. Some coding skill is required if you haven’t invested in tooling.
Figure 5. Rating the practice of database refactoring by data quality technique factors.
9. Parting Thoughts
Database refactoring supports an incremental approach to the evolution of your database schema, one of the three fundamental strategies (you can give up, take a “big bang release” approach, take an incremental approach). Each strategy has its unique strengths and weaknesses. I suspect that many organizations, perhaps because of a serial mindset, have either tried the big-bang release approach or have been too scared to do so and have now given up. It doesn’t have to be this way. Yes, it will likely take a significant effort for your organization to put the culture and technologies in place to support refactoring databases across your enterprise, but in the long run this is likely far more palatable than your other alternatives.
See the Catalog of Database Refactorings.
Regardless of your strategy database evolution is hard, something that is particularly true when your database is highly coupled to other things. Database refactoring is not a silver bullet that’s going to magically solve all of your database problems.
10. Related Resources
- The Agile Database Techniques Stack
- Automated database regression testing
- The Catalog of Database Refactorings
- Clean Database Design
- Data Debt: Understanding Enterprise Data Quality Problems
- Database Refactoring
- Database Refactoring: The Process to Fix Production Databases
- Introduction to DataOps: Bringing Databases Into DevOps