
Database Testing: What to Test For in a Database
Database management systems (DBMSs) are used to persist mission-critical data and implement mission-critical functionality. These DBMSs, henceforth referred to simply as databases, may be based on relational, hierarchical, network, or some other technical architecture. Database testing is the act of verifying that a database, also known as a data store, contains the data that you expect it to and exhibits the behaviours that you expect it to have. In this article, I explore what to test for, or more accurately, what to look for, when testing a database.
This article explores:
- Why database testing?
- Functional testing
- Relationship testing
- Data quality testing
- Database performance testing
- Structural testing
- Parting thoughts
1. Why Database Testing?
Given that data quality is critical to the success of our organizations, the impact of poor quality data is high. We’ve known for years that effective testing enables you to improve quality, and in particular testing often and early in the lifecycle can do so dramatically. It seems to me that to improve database quality that an important activity, if not the most important one, is to test our databases often (and better yet automatically). My experience is that databases, just like any other information technology (IT) component, can and should be tested according to the risk.
Database testing is an important part of agile testing and should be an important part of traditional approaches to testing as well. Figure 1 indicates what you should consider testing when it comes to databases. The diagram reflects the point of view of a single database, the dashed lines represent threat boundaries, indicating that you need to consider threats both internal to the database (clear box testing) and at the interface to the database (black box testing).
Figure 1. What to test in a database (click to enlarge).
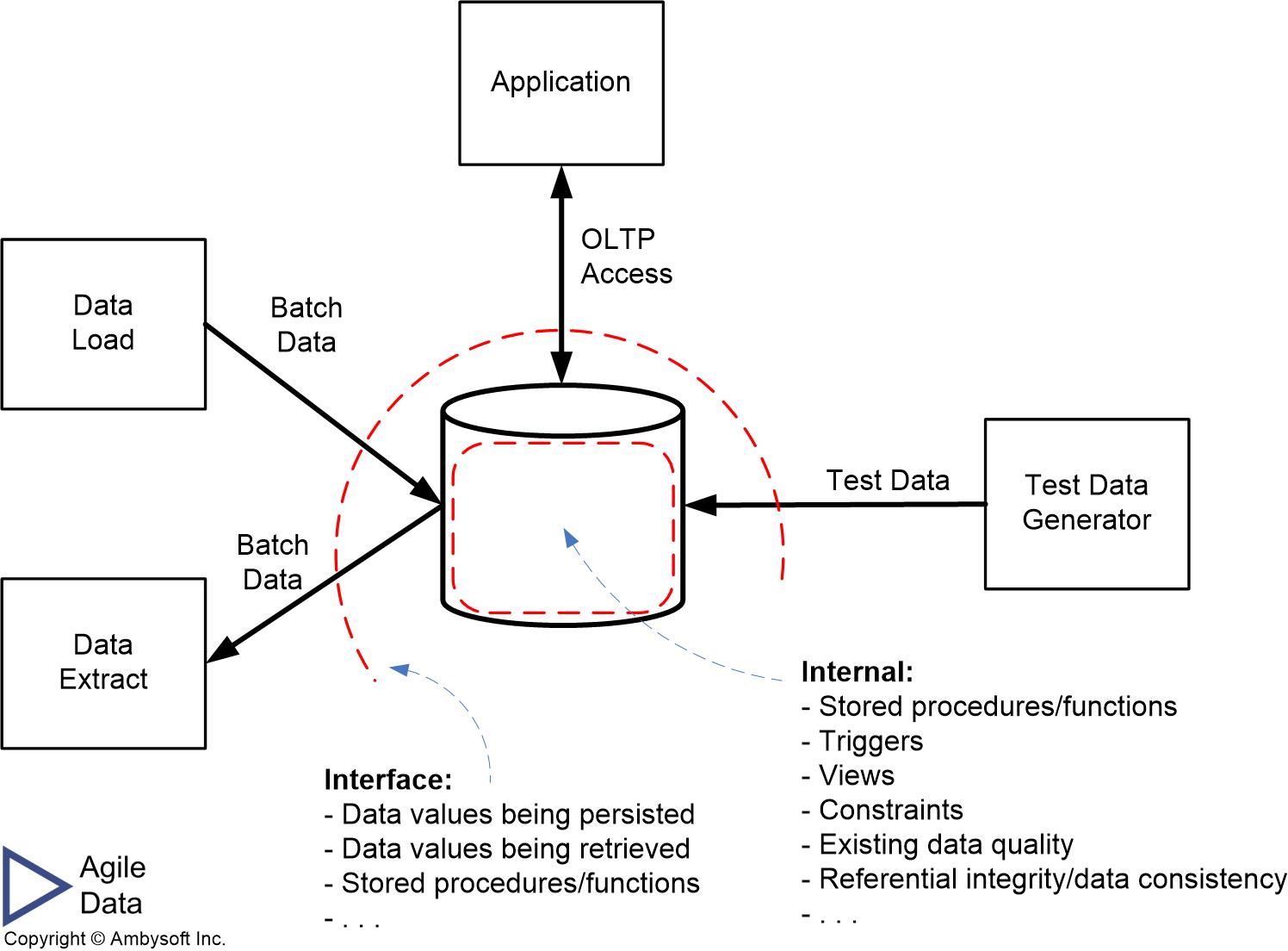
As you know, different data technologies use different terminology – there is no consistent, standard terminology. To address this, Table 1 captures the terminology that I will be using in this article to describe database testing concepts. The first column indicates the term that I will be using and the second column potential synonyms for that term that vary based on the underlying technology that you’re working with.
Table 1. Common terms and synonyms.
| Term | Potential Synonym(s) |
| Database | Data store |
| Structure | Table, Entity Type, View |
| Record | Row, Entity |
| Field | Column, Feature, Data Attribute, Attribute |
| Method | Stored procedure, stored function, function, trigger |
Let’s explore the major categories of database testing.
2. Database Testing: Functionality Testing
Functionality testing, also called code testing, refers to the act of ensure that the functionality implemented in your database works as expected. For a relational database this is stored procedures, stored functions, and triggers. In short, anything implemented as executing code within a database is considered functionality. From a testing point of view there is nothing special about database functionality – it should be tested just like any other type of code.
There are many great sources of information about functionality testing. As a result I’m not going to go into great detail about and instead will point you at some good resources. These resources include:
A significant portion of database functionality, in particular triggers, is automatically generated by software-based modeling tools (SBMTs) such as ER/Win. This begs the question “how much testing of generated code do I really need to do?”. Fair enough. Here is my advice:
- Test for existence. Methods can easily be dropped or renamed. In relational databases a common practice (still!) is to drop all of the triggers when doing a large batch data load and then restoring them after doing so. This is done for performance reasons. The challenge is that you don’t want to assume that all of the triggers were restored, instead you want automated tests to verify that this is so.
- Test for referential integrity (RI). Methods, in particular triggers, implement critical functionality to ensure referential integrity. Or at least they should. How do you know that RI is being properly implemented in your database? Automated tests. See below for a discussion of RI testing.
- Test your calculations. Any method that performs a calculation, even something simple like summing data, should be fully tested. A function is a function, it needs to be tested, regardless of where it is implemented.
- Test view definitions. Views in relational databases often implement interesting functionality. Things to look out for include: Does the filtering/select logic work properly? Do you get back the right number of records? Are you returning the right fields? Are the fields, and records, in the right order
3. Database Testing: Relationship Testing
Relationship testing focuses on ensuring that referential integrity (RI) is maintained. RI refers to the concept that when one record refers to, or links to, another record that this information is correct. For example, if there is a record indicating that Sally Jones is the owner of a given car, then both Sally and the car exist in the database.
This is true even in non-relational databases that only ensure eventually consistent transactions rather than ACID (atomic, consistent, isolated, and durable) transactions. With ACID the implication is that RI should hold once the transaction runs, even if the transaction isn’t successful. With eventual consistency RI should hold at some point, but it make take a bit of time. As you can see, testing to ensure RI with technology that ensures eventual consistency is harder than with ACID. That doesn’t mean that an eventual consistency strategy is bad, there are many valid architectural reasons to take such an approach, it just means that you’ll pay the price for doing so when testing. Go in eyes wide open.
RI rules are typically implemented in methods, particularly triggers in relational databases, or via assertions in the database. Regardless of how RI rules are implemented, they need to be validated. Potential RI issues to look out for when database testing include:
- Cascading deletes. The primary concern here is whether highly coupled “child” records are deleted when the parent record is deleted. For example, if an order is comprised of a collection of order items, when you delete the order you should also delete the corresponding order items. If an order item can be comprised of order items itself, a recursive relationship, then those order items should also be automatically deleted. And so on and so on. We say that the delete cascades across the aggregation of records. As you can imagine, you want to be very careful when you define cascading deletes. It makes sense to delete the order item records when you delete an order, it likely doesn’t make sense to delete the corresponding customer record for the order. Or perhaps it does, this depends on your business rules.
- Existence rules. When you insert an account record for a customer, does the corresponding customer actually exist? Existence rules can drive the order in which records are inserted into your database, and in some cases several records may need to be inserted as a single transaction so as to maintain RI within your database (see the point about collections). These rules need to be validated.
- Data collections. I’m using the term “data collection” to refer to a collection of strongly related records. For example, a bill of materials is a collection of strongly related records. So is a project schedule (a collection of very inter-related tasks). The issue that you need to test for is whether the referential integrity within a data collection is maintained whenever its data records are manipulated (inserted, updated, or deleted). In one way you can see these updates as a combination of cascading deletes and existence rules. As a result, from a testing point of view this is a combination of unit test (of each cascading delete and existence rule) and integration testing (of the combination).
4. Database Testing: Data Quality Testing
The focus of data quality testing is to ensure that the data values stored in your database are of sufficiently high quality. Automated database regression testing is required because data quality can degrade over time. This can happen for several reasons:
- New client systems may not reflect your existing data rules.
- Developers working on existing client systems may not understand the implications of the changes that they’re being asked to make.
- New requirements around data quality may be introduced – suddenly what used to be an acceptable level of quality no longer is.
The challenge is that “sufficiently high quality” depends on your context. Ideally you want perfect data, but this may not be economically achievable nor required. When it comes to data quality, I lean towards a “better is usually better” philosophy. I say usually better, rather than always better, because quality comes at a cost. Our real goal should be to maximize data value, not maximize data quality. So aim for the right level of data quality for your situation, rather than perfect data quality.
When it comes to data quality testing, common issues to look for include:
- Default values. A subset of your fields will have default values defined for them. Minimally I would test to ensure that the default values actually being assigned. The challenge is that it’s easy enough for someone to have accidentally removed this part of the table/structure definition without understanding the implication of doing so.
- Null values. Is the value of a field NULL when it shouldn’t be? Similarly, is a character field empty/blank when it shouldn’t be? Is the value of a numeric field zero when it shouldn’t be?
- Data invariants. A field may have one or more invariants, implemented in the forms of constraints, defined for it. For example, a number field may be restricted to containing the values 1 through 7. These invariants should be tested because once again it’s easy enough to alter or even drop constraints.
- Attribute size. Does the field size defined in your application code match how it is stored in the database? For example, is the first name field twenty characters in both spots, or is the application only working with twenty characters when it’s being stored as thirty in the database?
- Format. There may be business rules around the format of a field, an issue that is of particular concern for strings. For example, many people store telephone numbers as strings (I wouldn’t do this, but many people do). What is the formatting rules around doing this? Do you include the country code or not? Do you include special characters, such as hyphens and parenthesis, and if so what are the acceptable ways of doing so. Is “4169671111” an acceptable value? What about “(416) 967-1111”? Or “416.967.1111”? Or “+1 (416) 967-1111”? Whatever the answer is, I’d put assertions (if an option) and maybe tests in place. Regular expression (RegEx) processing can address this issue.
- Freshness. Is the data up to date? This can be an issue at the field, row, column, table, or even data source level.
- Type. Are the right database types being used? For example, is someone storing dates as strings rather than date time stamps? Are numbers being stored as strings?
- Single purpose. A field should be used for one purpose and one purpose only. Back when DASD (direct access storage device, what we used to call digital storage space back in the ancient times) was expensive it was common to do whatever you could to reduce storage needs. One trick was to use a field to store similar data values, such as a date, then have a second indicator field to indicate the type of date. For example, an employee’s start date, promotion date, and termination date might be stored in a single date field with a second one character column with values of ‘S’, ‘P’, and ‘T’ respectively to indicate the date type. This would save several bytes per record, as compared with having a date field for each historical event. You’d think people wouldn’t do this any more, but I still run into this sort of thing from time to time.
- Purpose normalization. The desire to have single purpose fields can be subtle. For example, we want to store the name of someone. Do we store that as a single field, say 80 characters in length, or as several fields? On for first name, middle name, surname, … and so on as needed? When highly normalized, with a field for each component of someone’s name, is each component field being used correctly? This can be particularly problematic when the external systems that update the data are operating in different contexts, say in North America, Asia, and the Middle East for example.
- Missing data. Is the data all there? For example, you expect transactional data from 324 stores every day but you received transactions for 323 stores yesterday.
- Volume. Is the volume of the incoming data what you expect? Is it currently surging?
5. Database Testing: Performance Testing
The focus of performance testing, as the name suggests, is to validate that something performs as well as, or better than, required. Automated regression tests to validate performance are important because performance can degrade over time as the amount of stored data grows or the number of simultaneous users increases.
When it comes to database performance testing an important decision that you need to make is one of scope. Are you testing the performance of just the database itself, effectively treating it as a unit? Or are you testing the end-to-end performance of your database plus the communication time between client systems and the database? In short, are you including infrastructure latency?
Issues to look out for when performance testing your database include:
- Access time to read/write/delete a single row.
- Execution time for common queries returning multiple rows.
- Execution time for queries involving several structures. Joins across multiple tables in a relational database, or traversals across structures in a non-relational database, can erode over time as the amount of data increases or the structures themselves evolve.
- Existence test for an index. In relational databases indices are used to improve the access performance. As with similar database features, indices can be dropped either accidentally or purposefully. It’s easy to test whether an index exists.
- Execution time for a transaction. Database transactions tend to represent fundamental units of work. Do they run sufficiently fast?
6. Database Testing: Structural Testing
Last but not least is structural testing. This is important because client applications expect that your database has a certain structure, unless of course the database (or at least a portion thereof) isn’t purposefully unstructured.
Structural issues that I look for when database testing include:
- Structure existence. We can check whether all the data structures that we expect to be there are in fact there.
- Naming conventions. Do the names of your structures, fields, methods, and the database itself follow the naming conventions of your organization? If such naming conventions do not yet exist in your organization, perhaps now is the time to start developing them. I prefer to implement the enforcement of naming conventions via static code/schema analysis tools.
7. Parting Thoughts
My experience is that database testing, in particular automated database regression testing, is the primary difference that separates organizations that are serious about data quality versus the ones that aspire to have sufficient data quality. Sadly, there are very few organizations that seem to be in this category. I believe that the virtual absence of discussion about testing within the data management community is a significant cause of the estimated $3T loss due to bad data annually by US organizations. We must choose to do better.
8. Related Resources
- An Introduction to Database Testing
- Automated Database Regression Testing
- Database Testing Terminology
- Introduction to DataOps
- Introduction to Test-Driven Development (TDD)