
Continuous Data Warehousing: A Disciplined Approach
This article overviews a disciplined approach to continuous data warehousing (DW)/business intelligence (BI). The focus of this article is on the process itself, as opposed to specific architecture and design techniques (for those, I highly suggest Data Vault 2). This article provides an overview of how continuous DW/BI works in practice, starting with an agile strategy based on Scrum and evolving it into a lean continuous delivery strategy that reflects the realities of the VUCA (volatile, uncertain, complex, and ambiguous) environment we face.
This article addresses:
- Introduction to Continuous DW/BI
- Continuous Data Warehousing: Release 1
- Continuous Data Warehousing: Release 2+
- Artifact Creation by Continuous DW Teams
- Where to Learn More
- Related Resources
1. Introduction to Continuous Data Warehousing/Business Intelligence
Let’s start with definitions of how I’m using several key terms in this article:
- Business intelligence (BI). The act of gathering, analyzing, presenting, and increasingly explaining (via AI) data for the use of data-informed decision-making.
- Continuous data warehousing/business intelligence. The act of building and evolving a DW/BI solution in a “DataOps/DevOps” manner. Updates to the DW/BI solution are delivered into production regularly, potentially several times a day.
- DataOps. The data-oriented aspects of DevOps. Another way to look at this is that DataOps is DevOps extended to address data issues.
- DevOps. A streamlined, continuous approach to IT solution development (dev) and operations (ops). The DevOps lifecycle is typically depicted as a Möbius loop.
- Data warehouse (DW). A structured source of high-quality data. Data warehouses typically encompass data from a range of legacy data sources.
- Data warehousing (DW). The act of creating and evolving a data warehouse.
- Way of thinking (WoT). Your mindset or paradigm towards a given subject.
- Way of working (WoW). The practices and processes (workflows, procedures, activities, …) that you follow.
1.1 Why Continuous Data Warehousing?
Data professionals, like everyone else, are working in a volatile, uncertain, complex, and ambiguous (VUCA) environment. To successfully navigate a VUCA environment, our stakeholders require access to high-quality, timely information that is easily consumable by them when and where they need it. Our organizations are building AI-based solutions to augment the activities of their staff and to better enable our customers, and to do that they also need high-quality data. Data warehouses are a critical source of that data, but only if they are populated and evolved in ways that reflect the VUCA realities we face. Continuous data warehousing, particularly one that leverages a DataVault 2 approach, addresses these needs.
1.2 Agile Data Roles
Figure 1 summarizes the roles that are pertinent to the Agile Data method. They are organized into two categories:
- Primary roles. These roles are the focus of the Agile Data method.
- Supporting roles. People in these roles collaborate with and support the work of people in the primary roles. These roles are adopted from other methods such as Scrum or Agile Modeling.
Figure 1. The Roles of the Agile Data Method (click to enlarge).

There are several important observations about these agile data warehousing roles:
- These roles are different from traditional roles. Yes, they use similar names to traditional roles although if it helps attach the word “Agile” onto the front of them at first. Moving to an agile/continuous WoW requires a paradigm shift. Part of that paradigm shift is an improved set of roles and responsibilities held by people on continuous data warehousing teams. As a professional, you need to be prepared to work in a new manner to fit into a new type of team.
- The era of the specialist is over. Key tenets of agile and continuous development are that people work together collaboratively to produce a working solution in an evolutionary (iterative and incremental) manner. An implication of that is that we’re no longer able to work in a manner where people with narrow specialties – such as logical data modeler, physical data modeler, data analyst, and data architect – each do their small part of the work and then hand it off to the next person. That traditional approach is too slow, expensive, and error-prone. Instead, we build teams of “T-skilled” generalizing specialists who have one or more specialties (such as the ones listed above) PLUS a broader set of skills and knowledge that allow them to take on a wider range of tasks and work more effectively with their teammates.
- There is room for you if you’re willing to learn. Although these roles are different than what you may be used to it is still possible, and highly desirable, for you to move into one of these roles.
- The need for specialists still exists. There is a very small range of situations where specialists are still needed. Having said that, it is highly unlikely that you’re in one of those situations. If you are new to agile, your best strategy is to assume that you are not in one of those situations and that you need to start working on becoming a generalizing specialist (not a generalist!) just like the vast majority of people.
1.3 Be Enterprise Aware
“Be enterprise aware” is one of the ways of thinking (WoT) of the Agile Data (AD) method. The observation is that DW/BI teams work within your organization’s enterprise ecosystem, as do all other teams. There are often existing systems currently in production, and at a minimum your solution shouldn’t impact them. Better yet, your solution will hopefully leverage existing functionality and data available in production. You will often have other teams working in parallel to your team, and you may wish to take advantage of a portion of what they’re doing and vice versa. Your organization may be working towards business or technical visions which your team should contribute to. A governance strategy exists which hopefully enhances what your team is doing.
It is important that continuous data warehousing teams work in an enterprise-aware manner for several reasons. You should:
- Adopt your organization’s development and data conventions. The implication is that your team will need to work closely with your organization’s enterprise architecture and data management teams who are typically responsible for such conventions.
- Leverage existing infrastructure wherever possible. You will want to work with your organization’s enterprise architecture team to understand the technical direction of your company and with your reuse engineering team (if you have one) to identify and leverage existing assets.
- Fix existing legacy systems and data sources whenever possible. Techniques such as database refactoring and data repair enable the owners of legacy data sources to safely address data quality (DQ) problems.
- Share learnings whenever possible.
- Be governed appropriately. Like it or not, your team is being governed. Effective IT organizations recognize that agile teams need to be governed in an agile, not a traditional, manner.
Your continuous data warehousing team will be affected, hopefully in a positive manner, by other teams running in parallel to you. Your team will work closely with the Enterprise Architects, your Data Architect may even be an EA, to understand their long-term vision. You will work with the Data Management group to understand and access existing legacy data sources. You’ll work with your Release Management and Operations teams to release your solution into production. Your Support/Help Desk team is likely providing enhancement requests and bug reports to your team. You may have dependencies on other delivery teams.
Not only must our team work in an enterprise-aware manner, but these other teams also need to be prepared to work in a more collaborative manner when interacting with our DW team. It will be very difficult for our DW team to work in a continuous manner if they rely on other teams who aren’t prepared, or worse yet sufficiently skilled, to work in a continuous manner too. Having said that, remember that your enterprise teams will need to support delivery teams working in a range of manners, not just continuous ones.
1.4 Choose the Right Lifecycle
As I describe below, my advice is that DW/BI teams new to continuous data warehousing should adopt:
- An agile project lifecycle for their first release, particularly if your data professionals are still learning agile and lean WoW.
- A lean continuous delivery “product” lifecycle for subsequent releases (if sufficiently skilled to do so).
1.3.1 First Release: Agile Project Lifecycle for DW/BI Teams
I need to be clear that the advice that I present in this section DOES NOT reflect a continuous DW/BI WoW. Instead it reflects a good starting point on your journey to a continuous WoW. Adopt this lifecycle when one or both of the following criteria are met:
- Your team is new to agile and lean ways of working. Such teams are best advised to start with an agile, Scrum-based approach because it is fairly straightforward and because it teaches you better behaviours. Scrum tends to be easier to adopt because it prescribes the timing of common practices (such as planning, demos, and retrospectives) and forces the team into delivering on a regular basis (each sprint). Unfortunately, this lifecycle does suffer from several problems that are better addressed by a continuous WoW.
- Your organization takes a project-based approach to funding. Many organizations fund new initiatives in terms of projects, something that is particularly true when your Project Management Office (PMO) has yet to evolve into a Value Management Office (VMO).
Figure 2 depicts a Scrum-based agile project lifecycle. This lifecycle deviates from the common Scrum lifecycle in two important ways. First, it depicts a three-phase delivery lifecycle, not just a single-phase construction lifecycle. Do agile lifecycles have phases? Yes! Second, it shows external inputs coming into the team from other areas of your organization.
Figure 2. The Agile Project Lifecycle (click to enlarge).
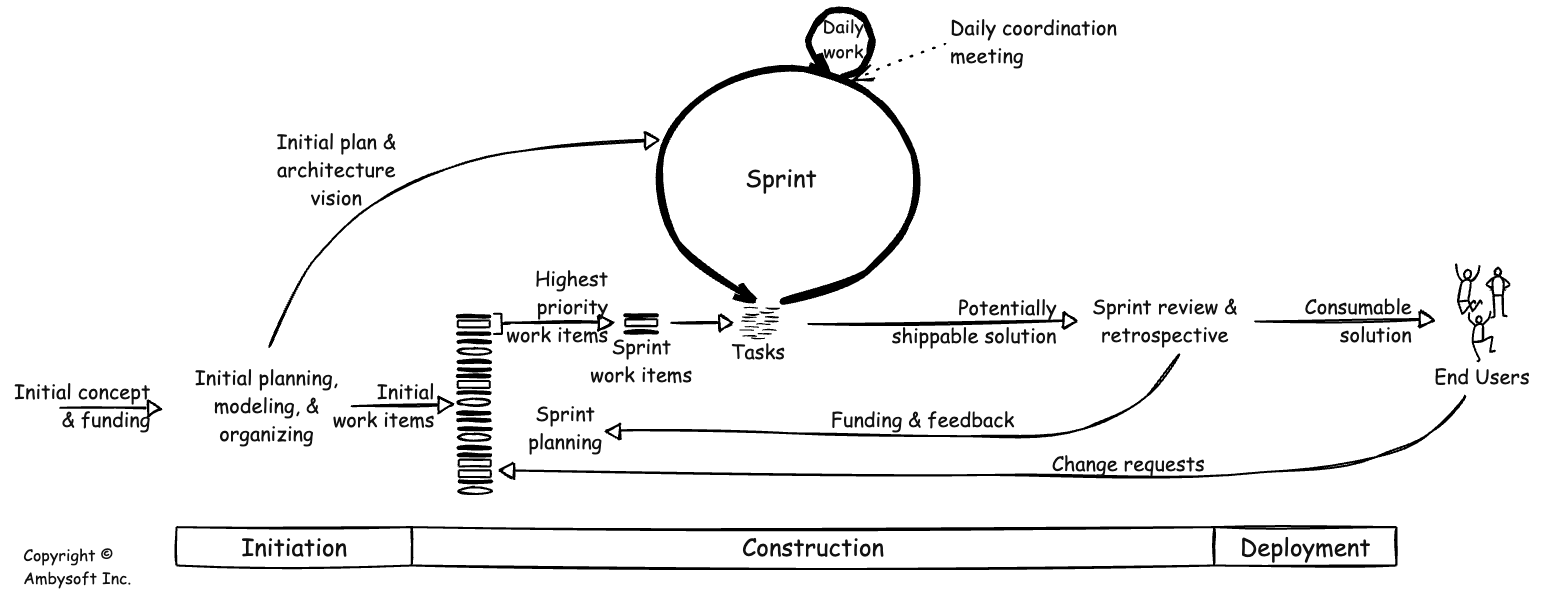
Although phase tends to be a swear word within the agile community, the reality is that the vast majority of teams do some up-front work at the beginning of an initiative. The Scrum-based lifecycle above explicitly calls out three phases:
- Initiation/Sprint 0. During this phase, team initiation activities occur, and this is often called an Initiation or Inception phase. These activities include initial scoping, initial architectural modeling, high-level release planning, putting the team together, starting into your risk management approach, setting up your work environment, and securing funding for the rest of the release. On average, this effort takes longer than a single sprint, even when you call it “Sprint 0”. During this phase, we conduct streamlined envisioning activities to properly frame the initiative. In greenfield environments, this may take longer than environments where you have an established infrastructure. For example, as part of your initial architecture activities, you may need to invest more time thinking through your architectural options and even run short experiments, such as spikes or proofs of concept. It takes discipline to keep Ideation short.
- Construction. During this phase, a disciplined team will produce a potentially consumable solution on an incremental basis. They may do so via a set of sprints/iterations or do so via a lean, continuous flow approach (not shown above). The team applies a hybrid of practices from agile, lean, and even traditional sources to deliver the solution. More on this later.
- Deploy. For many teams, deploying the solution to their stakeholders is often a complex exercise. Continuous DW/BI teams, as well as the enterprise overall, will streamline their deployment processes so that over time this phase becomes shorter and ideally disappears as a result of adopting continuous deployment strategies. It takes discipline to evolve deployment from a phase to an activity.
Continuous data warehousing teams working on their first release are likely to follow a project-based approach. Because they are working on the first release, they will need to invest time in basic initiation efforts discussed earlier. A detailed description of the type of activities that occur during each phase appears later in this article.
1.3.2 Subsequent Releases: Lean Product Lifecycle for Continuous Data Warehousing Teams
Figure 3 depicts a lean continuous delivery lifecycle. This lifecycle is often followed by continuous data warehousing teams that are evolving an existing DW/BI solution already running in production. The requirements for such solutions often come in regularly from stakeholders rather than in a large batch. These requirements are often small in nature, typically adding a new data field, updating an existing report or data download, or adding a new report/download. Furthermore, these requirements are self-contained and can be added easily to a well-architected DW/BI solution. Many of these requirements can be implemented in a few hours or days, so it often makes sense to do the work right away and release the new functionality as soon as you can. The temporal overhead of iterations/sprints, let alone regularly scheduled releases, in the Scrum-based lifecycle often doesn’t make sense for evolving an existing production DW, which is why a different approach is needed.
Figure 3. A Lean Continuous Delivery Lifecycle (click to enlarge).
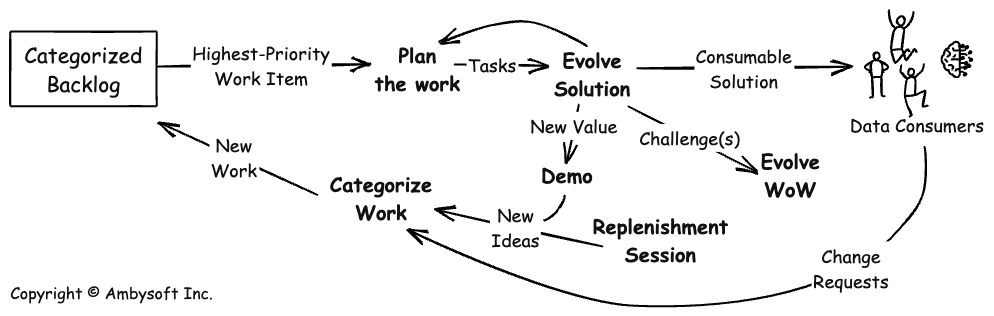
The Lean Continuous Delivery lifecycle of Figure 3 varies from the Scrum-based lifecycle of Figure 2 in several important ways:
- It supports a continuous flow of delivery. In this lifecycle, the solution is deployed as often and whenever it makes sense to do so. Work is pulled into the team when there is capacity to do it, not as part of a sprint’s regular heartbeat. This enables your data warehousing team to be more responsive to stakeholders.
- Practices are on their own cadences. With sprints, many practices (detailed planning, retrospectives, demos, detailed modelling, and so on) are effectively put on the same cadence, that of the iteration. With a lean approach, the observation is that you should do something when it makes sense to do it, not when the calendar indicates that you’re scheduled to do it. This enables you to streamline your activities more, BUT requires greater discipline.
- It has a categorized backlog. All work items are not created equal. Although you may choose to prioritize some work in the “standard” manner, such as a value-driven approach as Scrum suggests, not all work may fit this strategy. Some work, particularly that resulting from legislation, is date-driven. Some work must be expedited, such as fixing a severe production problem. Some work is oriented towards the health of your team, such as training, or the health of your product, such as refactoring. A JIT prioritization strategy, rather than a prioritized stack (as in the Scrum-based lifecycle), makes a bit more sense when you recognize these realities.
Note that the one thing that Figure 3 is missing is the depiction of an explicit ideation/initiation phase. As indicated earlier, the assumption is that you initiated this endeavour using the agile project-based approach depicted in Figure 2. The lifecycle of Figure 3 is adopted sometime after the first release, or perhaps even evolved into during the first release, replacing the Construction and Deploy phases of Figure 2.
1.5 Adopt DataVault 2
The approach described in this article works with any data warehousing method, including Inmon, Kimball, Data Vault 2 (DV2), data lake houses, and others. And yes, it works with strategies such as data mesh, data fabrics, and whatever else the vendors hope to sell you.
However, I recommend adopting DV2. DV2 provides a proven, solid strategy that addresses performance, auditability, reliability, and many other issues that are critical to your success. More importantly, DV2 addresses these issues at scale. The challenge is that many of the other methodologies leave these critical issues up to you. This can prove to be expensive and error-prone in practice. The bottom line is that the creators of DV2 have decades of experience succeeding at building data warehouses in a wide range of situations. It makes a lot of sense to leverage their expertise.
2. Continuous Data Warehousing
Let’s explore how a continuous data-warehousing team operates in practice. Table 1 summarizes the primary and secondary development activities that the team may perform. Primary activities are those that add direct value to the development effort. Secondary activities tend to focus on long-term documentation that may add value in the future, but the value proposition tends to be dubious in practice, so you want to be very careful in how much effort you invest in them. I tend to think of these as sideline activities that I would only do if the team has time to spare from primary activities.
Table 1. Activities on an Agile Data Warehousing Team.
| Phase | Focus | Primary Activities | Secondary Activities |
| Initiation/ Sprint 0 / Ideation |
|
|
|
| Construction |
|
|
|
| Deploy |
|
|
|
For now, we’ll assume that your team is working on the first release of a DW solution. As a result you will need to take a three-phase approach. For teams working with an existing DW solution that is already running in production, you may find that you do not need to work through Ideation (or at least you only need an abbreviated version of it).
2.1 The Initiation/Sprint 0 Phase for Continuous Data Warehousing Teams
During the Initiation phase – also known as Sprint 0, Ideation, or Inception – the team strives to perform just enough work to get going in the right direction. Disciplined teams will spend a few days or perhaps a week or so to do so, not several weeks or months. The key is that they work in a very streamlined manner.
Potential primary activities on an agile data warehousing team include:
- Initial usage modeling. Continuous DW teams take a usage-driven, not a data-driven approach to modeling. Understanding the data is still important, don’t get me wrong, it is just that it isn’t anywhere near as important as understanding how the data will be used. For data-oriented requirements you are better to write question stories which are an extension of user stories. Examples of question stories that would support the development of a DW/BI solution for a retail bank include “As a Branch Manager I need to analyze the portfolio of a customer so that we can target services to them”, “As a Branch Manager I need to explore the transactions occurring in my branch so that I better understand my customer needs”, or “As a Mortgage Officer I need to explore the risk profile of a potential mortgage holder so that I can decide how much we can loan that person.” Notice how all of these requirements focused on usage, not data details. The details can come later.
- Initial conceptual modeling. An important, supporting model to the usage model is a high-level conceptual model, sometimes called a domain model. This diagram should indicate the main entity types within the domain and the relationships between them. It does not need to indicate potential data elements, nor does it need to be perfect, it just needs to be reasonably close at this time. The goal is to gain a reasonable understanding of domain terms at this time, the details will emerge later during construction. For the banking application the domain model may indicate entity types such as Customer, Account, Mortgage, Loan, Branch, Portfolio, and perhaps another twenty or so entity types.
- Identification of potential data sources. Early in a DW/BI initiative, the team needs to identify the main (potential) sources of data. This information is often captured on a network diagram, or something similar. This diagram will overview the flow of information within your technical architecture, indicating the potential data sources, how information is obtained from those sources (see next activity), and how the data flows through your firewalls, staging areas (if any), your data warehouse(s), and any data mart(s).
- High-level data source analysis/profiling. During Initiation, you will want to obtain basic information about potential data sources as who the primary contacts are, what type of data it contains, how is that data accessed (e.g. via file transfers, via SQL queries, via web services, and so on), and sizing information (e.g. volume of data and rate of change). The goal right now is to gain sufficient understanding of the data sources so you can make intelligent architecture decisions about them.
- Initial architectural modeling. Early in an agile DW/BI initiative you want to identify a viable architectural strategy. Part of that strategy will be identifying potential data sources; part will be identifying how data will flow from the data sources to the target data warehouse(s) or data marts; and part will be making that flow work through combinations of data extraction, data transformation, and data loading capabilities. The layout of the technical architecture is often captured using a network diagram, discussed earlier. Architectural notes, in particular important technical decisions as well as good things to know (such as the data source information described earlier), are often captured in an Architectural Handbook. This handbook is often implemented as a collection of wiki pages so that anyone who is interested may have access to the information.
- Initial release planning. Contrary to what you may have heard, agile data warehousing teams perform some high-level release planning. Teams are often required to guesstimate the potential cost of the release they are working on as well as the potential delivery date. These guesstimates, or estimates if you prefer, are best presented as ranges so as to reflect the uncertainty of the information the guesstimate is based upon.
- Adopt common guidelines. Effective agile teams are enterprise aware, an aspect of which means that they strive to adopt and then follow common guidelines. These guidelines include data guidelines, security standards, coding guidelines, user interface guidelines, and many others.
- Leverage and potentially evolve existing enterprise metadata. If your organization has an enterprise taxonomy and ontology then you should use this information where necessary. You may even find, sometimes, that it is out of date and needs to be evolved. If your organization does not have this metadata then now is the time to start gathering it.
- Initiate a data testing strategy. Testing is so important on continuous data warehousing teams that we do it all the way through the lifecycle, not just during a testing phase at the end of the lifecycle. This includes the testing of all functionality, including database functionality and data-value testing. There are many things that can be tested pertaining to databases, see Database Testing: How to Regression Test a Relational Database for some thoughts on the subject. Your data testing strategy should address issues such as how to test extract-transform-load (ETL) logic, how to validate data sources, how to ensure the quality of the data in the data warehouse(s) and data mart(s), what tools will be used, and identification of who has the skills to do the work. This may be the greatest challenge faced by traditional data professionals as they adopt agile ways of working (WoW) – not only do few traditional data professionals have data testing skills the vast majority don’t even realize how critical those skills actually are.
Potential secondary activities include:
- Detailed data modeling (partial). You may need to start doing some data modeling, both logical data model (LDM) and physical data model (PDM) development, during Initiation. Your LDM, if you create it at all, is typically used for detailed data analysis, an activity which occurs during Construction. Similarly your PDM(s) are used to design the database schema of your DW and data mart(s), also work that is typically done during Construction. Having said that, during Ideation you may choose to do detailed look-ahead modeling of high-priority requirements, and the design to support them, that you intend to implement in the first iteration or two of Construction. As a result you MIGHT do some data modeling work, see below for a more detailed discussion of what that might entail.
- Data lineage mapping (initial). Part of your look-ahead analysis effort, sometimes called “backlog refinement” by Scrum practitioners, will be to do just enough data mapping to implement the first few stories in your backlog. You need to know where the data is coming from to implement just these stories. Yes, any given data source may have hundreds of data elements that your team may potentially be interested in at some point, but for now you just need to map the handful of data elements required to implement the first few stories. That’s it. Future data lineage mapping will be performed in an evolutionary manner throughout construction.
- Detailed data source analysis (partial). Similarly, you will do just enough analysis of your data sources to understand just the data elements required for the first few requirements.
2.2 The Construction Phase for Continuous Data Warehousing Teams
You are likely to adopt a collection of activities as we saw in Table 1 above. Potential primary activities include:
- Development of vertical, fully functional slices. Each sprint the DW/BI team will produce a solution that is consumable, something that could be potentially shipped into production that people want to actually use. This means that you will analyse, design, implement, and test that functionality during the iteration (and most agile teams work in iterations that are two weeks in length or less). This is why it is so important to take a usage-driven approach and not a data-driven approach – your team needs to always be working on some new functionality that adds real value to your stakeholders. In a given iteration you do the work to completely implement one or more reports, or perhaps a portion of a report or an enhancement to an existing report, in a single iteration. You will extract the data from the data source(s), transform/clean it, and load it into the DW. This can be tough initially because you will not have the infrastructure in place yet during the first few Construction iterations. For example, the first time you extract data from a data source, you’ll need to do a lot of the work to access that data source. You can read more about implementing a data warehouse via vertical slicing.
- Prove the architecture with working code. There are always technical risks on DW initiatives. Maybe the technologies that you’re working with are new to your organization. Maybe several data sources are difficult to work with, either because the owners of the data sources are difficult, because there are quality issues with the data, because there are architectural differences between the data sources (e.g some are real-time and some are batch systems), or perhaps because there are volume challenges (i.e. “big data”). Disciplined DW teams remove these sorts of risks by implementing functional requirements that touch on the risks right away. Worried about accessing data from a batch system? Start by writing a report that needs data from it. Worried about whether your ETL tool is going to work well? Implement one or more requirements that require the key features of that tool. Worried about whether you’ll be able to handle the big data load? Implement a requirement that needs that data. Often, traditional teams, and even undisciplined agile teams, defer the hard aspects of their architecture to the end of the lifecycle, thereby increasing the potential costs of fixing problems they encounter. Effective DW teams prefer to address their risks as early as they can, when they have the most time and resources to respond to the problems.
- Detailed data source analysis. Data source analysis occurs on a just-in-time (JIT), or near-JIT basis. Your team will do the analysis required to implement the current requirements (let’s assume they’re captured as user stories). So, if a question story requires data from three data sources, then you will do the analysis for those data elements from those sources. Of course, you’re likely doing the analysis for several stories at a time, perhaps five or six stories. Furthermore, continuous data warehousing teams will be doing look-ahead modeling, described earlier, where you are doing the analysis for stories that are coming up in the next iteration or two. The basic strategy is to have just enough data source analysis done before you go to implement the actual functionality. You are likely to do more data source analysis in earlier Construction iterations as opposed to later iterations – as you populate your DW, the data required for new reports or queries is more likely to be there over time. Traditional teams have a tendency to do comprehensive data source analysis one data source at a time, followed by the implementation work needed to obtain and then load the data into the DW. This appears efficient from the point of view of the person(s) doing the work, but proves to be rather inefficient in practice from the point of view of your stakeholders for two reasons. First, it takes much longer to get to the point where you have sufficient data in place to implement the reports, or to support answering their questions, that they actually want. In other words, you have a very high cost of delay (also referred to as opportunity cost). Second, you end up analyzing (and then implementing) data elements that aren’t actually needed.
- Implementation to get data from your sources into your vault. The implementation work to extract the data from source, transform the data as required, and then load it into your target database(s) will be done in a JIT, evolutionary manner. Each sprint your team will do the work to implement one or more stories from end-to-end (e.g. vertical slices through your solution) and part of this work is the implementation of the data lineage mappings, ideally using tools that maintain lineage meta data.
- Database refactoring. A refactoring is a simple change to your design that improves its quality without changing its semantics in a practical manner. A database refactoring is a simple change to a database schema that improves the quality of its design OR improves the quality of the data that it contains. Database refactoring enables you to safely and easily evolve database schemas, including production database schemas, over time. This technique, in combination with database regression testing and continuous integration, allow us to develop data warehouses, or any solution involving a database for that matter, in an agile manner.
- Physical data modeling. The physical data model(PDM)s describing your databases, including both source and target databases, will evolve throughout Construction. Please see the article Agile/Evolutionary Data Modeling for a detailed description for how to go about agile data modeling.
- Regression testing. Quality is paramount for continuous data warehousing teams. Disciplined teams will develop, in an evolutionary manner of course, a regression test suite that validates their work. They will run this test suite many times a day so as to detect any problems as early as possible so that they can address them as cheaply as possible (remember, the average cost of fixing a defect rises exponentially the longer it takes you to find it). In fact, very disciplined teams will take a test-driven development (TDD) approach where they write tests before they do the work to implement the functionality that the tests validate. As a result the tests do double duty – they validate and they specify (which is one of many reasons why agile teams require far less documentation than traditional teams, their specifications are in effect executable as opposed to static). Please see Database Testing: How to Regression Test a Relational Database for a more detailed description of this strategy.
- Continuous integration (CI). Continuous integration (CI) is a technique where you automatically build and test your system every time someone checks in a code change. Continuous database integration (CDI) is the database version of CI (persistent data adds a few challenges for CI). Data engineers will typically update a few lines of code, or make a small change to a configuration file, or make a small change to a PDM and then check their work into their configuration management tool. The CDI tool monitors this, and when it detects a check in it automatically kicks off the build and regression test suite in the background. This provides very quick feedback to team members, enabling them to detect issues early.
- Continuous deployment (CD). When an integration build is successful (it compiles and passes all tests) your CD tool will automatically deploy to the next more appropriate environment(s). Continuous database deployment (CDD) is the database version of CD (once again, persistent data adds a few challenges to CD). For example, if the build runs successfully on a data engineer’s work station their changes are propagated automatically into the team integration environment (which automatically invokes CI in that space). When the build is successful in your team integration environment perhaps it’s promoted into an integration testing environment, and so on.
- Continuous documentation. Your team should be solution focused, not just software focused. Because documentation is part of the overall solution that you deliver, you should be develop key documentation (system overview documentation, help guidelines, and so on) as you develop the software. For more information, see the Agile Modeling practice document continuously.
- Detailed planning. Planning is so important on continuous data warehousing teams that we do it all the way through Construction. Detailed planning occurs at the beginning of each iteration (for teams following the Scrum-based lifecycle) or in an as-needed, just in time (JIT) manner (for teams following the lean/continuous delivery lifecycle). Team members may also choose to engage in look-ahead planning to begin thinking through the next iteration or two in complex situations.
- Coordination meetings. The team needs to coordinate their work both internally within the team and externally with other teams.
- Demos. Disciplined teams demonstrate their work on a regular basis, typically at the end of each sprint. This demo, typically run by your backlog owner, shows off the work that your team has accomplished since the last demo. Because you are taking a usage-driven approach, each sprint you should have added more functionality that provides real value to your stakeholders. For example, your demo typically walks through how you implemented several question stories since your last demo.
- Retrospectives. One of the principles behind the Agile Manifesto is that teams should regularly reflect on what they’re doing and strive to learn and improve their approach. Retrospectives are a simple technique for doing exactly that.
Potential secondary activities include:
- Logical data modeling. If you do decide to invest time in an LDM, keep it as streamlined as possible and DO NOT allow this effort to slow down development. If you think that your LDM can offer actual value to your organization, then ask yourself how you can add the same value using automated tests.
- Documentation of data lineage. If you find that you need to resort to documentation, remain as agile as possible and keep the documentation concise. Please see Agile/Lean Documentation Strategies for more ideas about how to keep your documentation concise and sufficient. However, if you believe that documentation would add value, then why haven’t you used a data lineage mapping tool that supports report generation? Generate required documentation, likely for auditability, rather than maintain it separately from your implementation.
- Meta-data documentation. Once again, follow agile documentation strategies for capturing any meta-data information.
2.3 The Deploy Phase for Continuous Data Warehousing Teams
During the Deploy phase the team strives to ensure that the solution is consumable, and when it is they deploy the solution. To address these process goals, you are likely to adopt a collection of activities as we saw in Figure 5 above. Potential primary activities include:
- End-of-lifecycle testing. Some testing may slip into the Deploy phase. Ideally all testing should occur during Construction, other than one last run of your regression test suite to ensure you’re ready to ship. But it isn’t always an ideal world. See end-of-lifecycle testing for more details.
- Last-minute fixes. If you perform end-of-lifecycle testing there is always the risk that the testing effort finds some bugs. Your Backlog Owner may decide that these bugs need to be fixed before you’re ready to ship.
- Finalize deliverable documentation. Some teams will let documentation slip, or at least some documentation slip, to the end of the lifecycle. This is a practice called Document Late, although I prefer a continuous documentation approach described earlier.
- Deploy database schema changes. Part of your overall deployment efforts will be to deploy database schema changes. If you’ve been taking a database refactoring approach then this will be very straightforward as your change scripts will already be running and fully testing. Before making the schema changes you should consider creating a backup of the database. You may find The Process of Database Refactoring: Install Into Production, to be an interesting read.
- Migrate production data to new schema. See The Process of Database Refactoring: Install Into Production.
The only potential secondary activity is to finalize any secondary documentation that you believe will add real value in the future.
Having said all of this, to truly be a continuous data warehousing team you must evolve your deployment phase into a deployment activity. You do this by fully automating the tasks above or by making those tasks (in particular writing documentation) a part of your normal construction process.
3. Continuous Data Warehousing: Releases 2+
The first release of many data warehouses is treated as a project. This decision typically reflects your internal funding processes rather than the nature of your data warehouse. A data warehouse, in practice, is a long-standing enterprise asset or capability. I say this because there is always more to build, since your stakeholders will always have new requirements. The implication is that You will need many releases of your data warehouse, not just one.
While it may be tempting for management to treat these new releases as projects, this would be a mistake. The reality is that the changes you’re being asked to make tend to be small. New requirements will typically be captured as question stories, which are, by definition, small. Production errors are usually small. Perhaps you need to update an existing calculation or view, or reconfigure a dashboard widget. The point is that these changes, being small, can be addressed in quickly, often in hours or a few days. Shouldn’t small changes be released when they are ready? Why would we want to wait months to release new value at the end of a project? Why not release them this evening if they are ready to go? This is at the heart of continuous data warehousing.
Your data warehouse is an enterprise asset/capability and should be treated as such. Such assets should follow a product-based strategy, sometimes referred to as a programme, rather than a project-based strategy. I highly recommend Nik Kersten’s book, Project to Product, to anyone who wants to understand why and how to move away from a project mindset for solution/product development.
4. Artifact Creation by DW Teams: Traditional vs. Agile
Figure 4 compares the typical level of expended effort creating artifacts on traditional and continuous data warehousing teams. There are several interesting differences to between the approaches. Continuous data warehousing teams will:
- Create a high-level conceptual model early. A high-level conceptual model, or more accurately diagram at this point, identifies the critical business entity types and the relationships between them. This provides vital insight into the domain while helping to capture key domain terminology, thus helping to drive consistency of wording in other artifacts (such as user stories and epics). Traditional teams will often make the mistake of over-documenting the conceptual model early in the lifecycle, injecting delay into the team (with the corresponding opportunity cost of doing so) as well as the risk of making important decisions when you and your stakeholders have the least knowledge of the actual end goal.
- Evolve a minimal logical data model (LDM) over time. If your continuous data warehousing team does this at all they will keep their LDM very concise and easy to evolve. Traditional teams will often invest heavily in their LDMs as they believe it is a mechanism to ensure quality and consistency through specifying it in. This often proves to be wishful thinking in practice. Disciplined teams instead invest their efforts in creating an executable specification in the form of regression tests (more on this below).
- Evolve a detailed physical data model (PDM) over time. Experienced teams realize that a PDM, when created via a data modeling tool with full round-trip engineering (it generates schemas as well as imports existing schemas), effectively becomes the source code for the database. As the requirements evolve the team will evolve the PDM to reflect these new needs, generating schema changes as needed. They can work this way because they can easily refactor and regression-test their database. This is different from the traditional approach where they often perform detailed modeling up front. This is motivated by the mistaken belief that production database schemas are difficult to evolve, something that database refactoring proves to not be true.
- Develop a comprehensive regression test suite over time. These tests address several important issues. First, they validate the team’s work, showing that their work to date meets the requirements as described to the team. Second, a regression test suite enables the team to safely evolve their work. Agile developers can make a small change, rerun their regression tests, and see whether they broke something (if so, then they either rollback their change or they fix what they broke). Third, when a test is written before the corresponding database schema or database code is developed, the test effectively becomes a detailed executable specification. Sophisticated agile data warehousing teams will capture the kinds of information that were previously captured in LDMs in executable tests, and are thus much more likely to have consistent schemas than teams that still rely on static LDMs.
- Capture critical meta-data over time. Because the rest of your organization may not be completely agile there is often a need to continue to capture key meta data about data sources. This meta data should be kept as light as possible. If there isn’t a definite need for it then don’t capture it. If someone says “but we might need it someday” then wait until someday and invest in capturing the information at that point. Furthermore, instead of capturing meta data in a static manner (i.e. as documentation) try to identify ways to capture it as tests, or to generate it automatically from other information sources. Any documentation that you write today needs to be maintained over time, slowing you down.
Figure 4. Comparing Artifact Creation by DW Teams (click to enlarge).

For a better understanding of why traditional DW teams are likely to write too much documentation far too early in the lifecycle, you should read the article The Cultural Impedance Mismatch.
5. Where to Learn More
I currently deliver two workshops about building a continuous enterprise data pipeline:
- Practitioner Workshop: How to Deliver Continuous Enterprise Data – This is a two-day workshop for data practitioners who want to learn how to build and evolve a continuous enterprise data pipeline.
- Leadership Workshop: How to Enable Continuous Enterprise Data – This is a half-to-one-day workshop for people who lead, govern, or work with enterprise data teams.
My book “Not Just Data: How to Deliver Continuous Enterprise Data“.
6. Related Resources
- Choosing the Right Sprint Length for an Agile Data Team
- Clean Database Design
- Data Vault Alliance
- Implementing a Data Warehouse via Vertical Slicing
- Implementing a Question Story in Data Vault 2: White Paper
- Core Practices for DW/BI Teams
- The Disciplined Agile Web Site
- The Agile Modeling Web Site
- Look-Ahead Data Analysis
- Question Stories
- Workshop: Continuous Data Warehousing (DW): A Disciplined Hybrid Method for Practitioners – Two days
- Workshop: Continuous Data Warehousing for Leaders – One day
Trademark Notice
“Disciplined Agile” is a registered trademark of Project Management Institute.