
Data Quality Techniques: How to Assess DQ Techniques
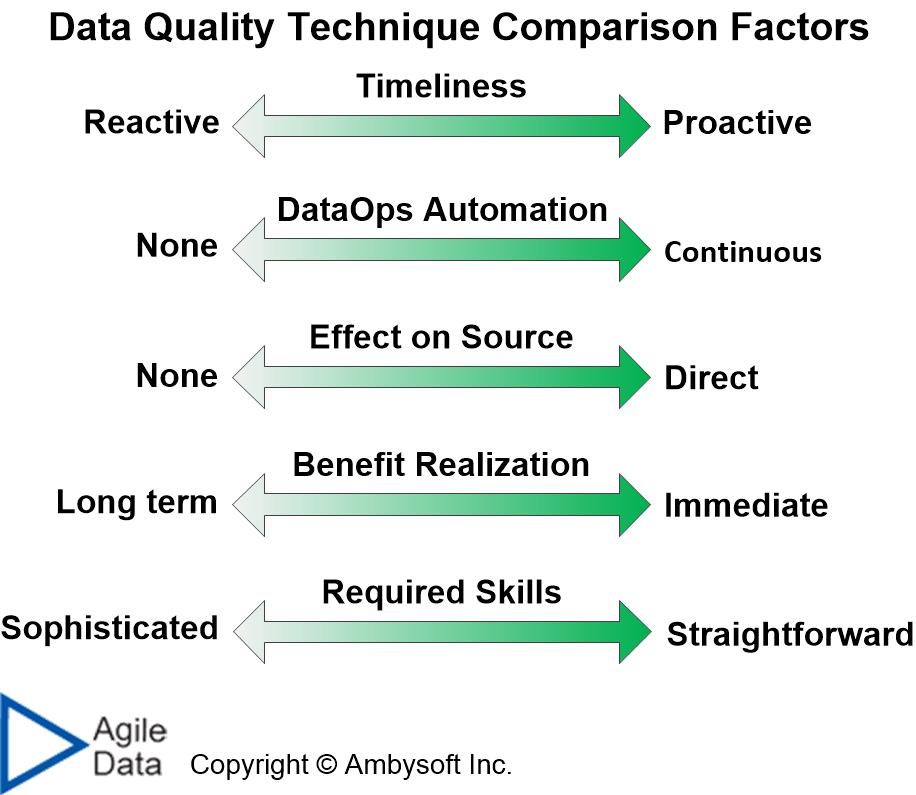
Data Quality Technique Comparison Factors
- Timeliness. Is this technique typically applied because you’re reacting to a discovered DQ issue or are you applying it to proactively avoid or reduce DQ issues?
- DataOps automation. What is the potential to apply automation to support this technique in your DataOps pipeline? A continuous technique would be fully automated and automatically invoked as appropriate.
- Effect on source. How much effect, if any, does this technique typically have on the actual source of the DQ issue? For example, data cleansing at point of usage (see assessment below) has no impact on the data source even though it may have significant impact on the data as it is used.
- Benefit realization. When do you attain the benefit, the quality improvement, resulting from the technique? Some techniques, such as data cleansing, provide immediate quality benefits. Other techniques, such as data stewardship, may require years for the quality benefits to be realized.
- Required skills. What is the level of skills required to successfully perform this DQ technique? Does it require sophisticated skills that may need to be gained through training or experience? Or is the technique straightforward requiring little effort, if any, to learn?
Figure 1. The data quality technique comparison factors.
Let’s consider two examples to see how these data quality comparison factors can be applied in practice.
Data Quality Technique Assessment: Database Refactoring
First, let’s assess the agile data practice of database refactoring from the point of view of data quality effectiveness. As a reminder, a database refactoring is a small change to the design of an existing database (even a production one) that improves the quality of the design without changing its semantics in a practical manner. The assessment results are depicted in Figure 2 below.
Figure 2. The effectiveness of database refactoring from the point of view of data quality.
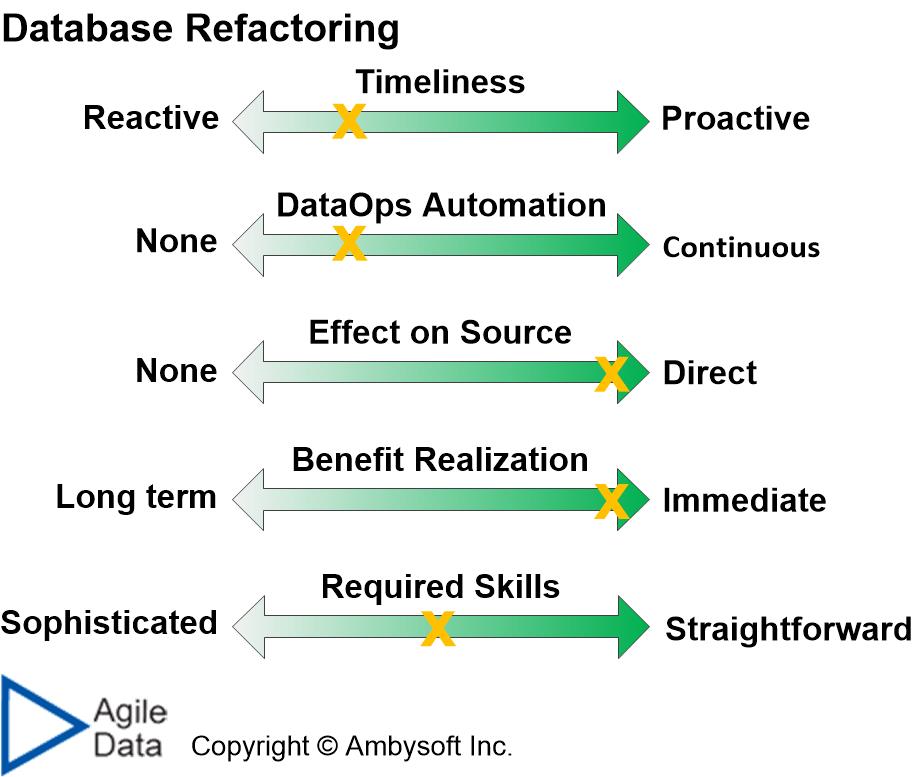
Wait a minute! Database refactoring didn’t get a perfect score on all five factors? How could that be? Once again, there’s no such thing as a best practice – every practice has its strengths and weaknesses, being a great idea in some contexts and a bad idea in others. Table 1 summarizes how database refactoring scored on each of the five factors.
Table 1. How database refactoring ranks on each of the five comparison factors.
| Technique | Score (1-5) | Explanation |
| Timeliness | 2 | For the most part database refactoring is a reactive technique. You find a DQ problem, often in a production data source, and then you choose to fix it. However, in some cases database refactoring occurs before a data source is deployed, or at least that version of a data source is deployed. In effect you’ve made a design mistake, realized it very soon afterwards, and addressed it before it became an actual problem. |
| DataOps automation | 2 | Database refactoring is mostly automated now, typically via open source tooling and sometimes even commercial tooling, to perform the majority of the work. But it is only the application of any changes into production, and the removal of old schema and scaffolding after the transition period, that should be part of your DataOps pipeline. This is a small part of the overall refactoring work, hence the low score. |
| Effect on source | 5 | Database refactoring is implemented directly on the data source. The change can be deployed immediately, even into a production database (barring any organizational policies preventing such action). |
| Benefit realization | 5 | The benefits are immediately realized due to the ability to deploy the change to the source immediately. |
| Required skills | 3 | Database refactoring requires the persons doing it to have at least fundamental data engineering skills. It also requires knowledge of your organization’s data conventions and data architecture to determine whether the identified improvement is appropriate. |
Data Quality Technique Assessment: Data Cleansing (at point of use)
Figure 3 depicts how data cleansing, at the point of use of the data, fares as a data quality technique. This is the classic approach to data cleansing commonly taken by data warehousing teams, application teams, and artificial intelligence (AI) teams. When the team needs data they bring it in from the source, analyze it, determine that there are quality problems, and then they clean the data before using it. Personally, I consider this form of data cleansing to be an option of last resort. Given the opportunity, I prefer to cleanse data at the source via data repair rather than at the point of usage. Table 2 summarizes how the technique scored on each of the five factors.
Figure 3. The effectiveness of data cleansing from the point of view of data quality.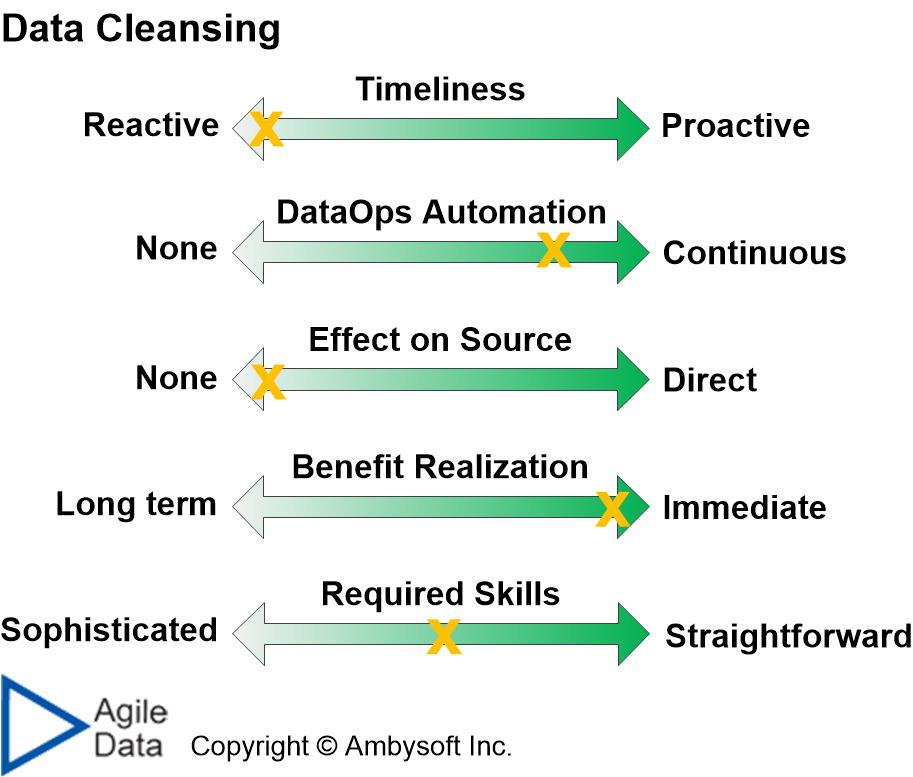
Table 2. How data cleansing (at point of use) ranks on each of the five comparison factors.
| Technique | Score (1-5) | Explanation |
| Timeliness | 1 | This is purely reactive – the data is cleansed at the point at which it is needed, often without the knowledge of the owner of the data source. |
| DataOps automation | 4 | There are some great data cleansing tools, even some applying AI-based technology, and they can be added into your DataOps pipeline as needed. |
| Effect on source | 1 | The data source isn’t updated as the result of this data cleansing effort. Mature teams will inform the owner of the data source of the types of DQ problems that they find. They do this in the hope that the owner will eventually fix the source. |
| Benefit realization | 5 | The benefit of data cleansing at the point of use is realized immediately by the team doing the work. |
| Required skills | 3 | Data cleansing typically requires fundamental data engineering skills to perform the work as well as domain knowledge to determine what work needs to be done. |
Other Potential Comparison Factors
You may be thinking that there are other factors that we should consider when assessing data quality techniques. In fact, I did consider, and then reject, two others. I rejected them because your environment has a significant influence over them, hence they need to be taken into account by you as part of determining the context of the situation that you face. These factors are:
- Cultural alignment. How well does the technique fit with the overall culture of your organization, your team, and your data professionals? For example, a data quality technique, say data stewardship, might technically be a great option for your situation. However, your organization tried to adopt a data stewardship program several years earlier and unfortunately failed at doing so. Asa result data stewardship is an unacceptable option for you.
- Value. What will the potential value be of applying the data quality technique? Value is defined in the classical sense as benefit minus cost. The potential benefit is driven by the size of the problem, something that is defined by your context not by the technique. Cost is driven by a combination of your context and of the technique.
Choosing the Right Data Quality Techniques for Your Context
The end game is to choose the right DQ techniques for you given the context that you face. For example, if you face a situation when you need to directly improve the quality of the data source and immediately benefit from doing so, then techniques in the top-right corner of Figure 4 would likely be your best choices. If a combination of other factors was important to you, say adopting techniques requiring a low level of automation and a low level of required skills, then techniques in the top left corner of Figure 5 would be attractive. Different situations drive different choices.
Figure 4. Comparing DQ techniques on effect on source and benefit realization.
Figure 5. Comparing data quality techniques based on level of automation and required skills.

In Summary
Every data quality practice has advantages and disadvantages. A given technique fits well in some situations and poorly in others. As a result the concept of “best practice” is better thought of as “best fit practice given your context”. In this article I walked through five comparison factors against which both data quality techniques and the situation that you face can be assessed. This enables you to determine which data quality technique(s) are the best fit for you, the topic of Data Quality Techniques: Choosing the Right DQ Techniques.
Related Resources
- The Agile Database Techniques Stack
- Clean Database Design
- Configuration management
- Continuous Database Integration (CDI)
- Data Cleansing: Applying The “5 Whys” To Get To The Root Cause
- Data Debt: Understanding Enterprise Data Quality Problems
- Data Quality in an Agile World
- Data Repair
- Database refactoring
- Database testing
- Test-Driven Development (TDD)