
Introduction to Data Normalization: Database Design 101
1. Why Data Normalization?
There are two primary advantages of having a highly normalized data schema:
- Increased consistency. Information is stored in one place and one place only, reducing the possibility of inconsistent data.
- Easier object-to-data mapping. Highly-normalized data schemas in general are closer conceptually to object-oriented schemas because the object-oriented goals of promoting high cohesion and loose coupling between classes results in similar solutions (at least from a data point of view).
You typically want to have highly normalized operational data stores (ODSs) and data warehouses (DWs).
The primary disadvantage of normalization is slower reporting performance. You will want to have a denormalized schema to support reporting, particularly in data marts.
2. The Steps of Data Normalization
Table 1 summarizes the three most common forms of normalization ( First normal form (1NF), Second normal form (2NF), and Third normal form (3NF)) describing how to put entity types into a series of increasing levels of normalization. Higher levels of data normalization are beyond the scope of this article. With respect to terminology, a data schema is considered to be at the level of normalization of its least normalized entity type. For example, if all of your entity types are at second normal form (2NF) or higher then we say that your data schema is at 2NF.
Table 1. Data Normalization Rules.
| Level | Rule |
| First normal form (1NF) | An entity type is in 1NF when it contains no repeating groups of data. |
| Second normal form (2NF) | An entity type is in 2NF when it is in 1NF and when all of its non-key attributes are fully dependent on its primary key. |
| Third normal form (3NF) | An entity type is in 3NF when it is in 2NF and when all of its attributes are directly dependent on the primary key. |
2.1. Data Normalization: First Normal Form (1NF)
Let’s consider an example. An entity type is in first normal form (1NF) when it contains no repeating groups of data. For example, in Figure 1 you see that there are several repeating attributes in the data Order0NF table – the ordered item information repeats nine times and the contact information is repeated twice, once for shipping information and once for billing information. Although this initial version of orders could work, what happens when an order has more than nine order items? Do you create additional order records for them? What about the vast majority of orders that only have one or two items? Do we really want to waste all that storage space in the database for the empty fields? Likely not. Furthermore, do you want to write the code required to process the nine copies of item information, even if it is only to marshal it back and forth between the appropriate number of objects. Once again, likely not.
Figure 1. An Initial Data Schema for Order (UML Notation).


2.2. Data Normalization: Second Normal Form (2NF)
Although the solution presented in Figure 2 is improved over that of Figure 1, it can be normalized further. Figure 3 presents the data schema of Figure 2 in second normal form (2NF). an entity type is in second normal form (2NF) when it is in 1NF and when every non-key attribute, any attribute that is not part of the primary key, is fully dependent on the primary key. This was definitely not the case with the OrderItem1NF table, therefore we need to introduce the new table Item2NF. The problem with OrderItem1NF is that item information, such as the name and price of an item, do not depend upon an order for that item. For example, if Hal Jordan orders three widgets and Oliver Queen orders five widgets, the facts that the item is called a “widget” and that the unit price is $19.95 is constant. This information depends on the concept of an item, not the concept of an order for an item, and therefore should not be stored in the order items table – therefore the Item2NF table was introduced. OrderItem2NF retained the TotalPriceExtended column, a calculated value that is the number of items ordered multiplied by the price of the item. The value of the SubtotalBeforeTax column within the Order2NF table is the total of the values of the total price extended for each of its order items.
Figure 3. An Order in 2NF (UML Notation).

2.3. Data Normalization: Third Normal Form (3NF)
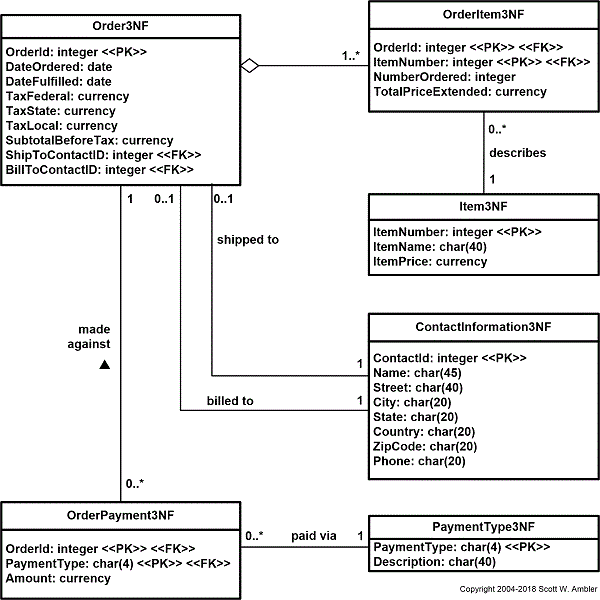
An entity type is in third normal form (3NF) when it is in 2NF and when all of its attributes are directly dependent on the primary key. A better way to word this rule might be that the attributes of an entity type must depend on all portions of the primary key. In this case there is a problem with the OrderPayment2NF table, the payment type description (such as “Mastercard” or “Check”) depends only on the payment type, not on the combination of the order id and the payment type. To resolve this problem the PaymentType3NF table was introduced in Figure 4, containing a description of the payment type as well as a unique identifier for each payment type.
Figure 4. An Order in 3NF(UML Notation).
2.4. Data Normalization: Beyond 3NF
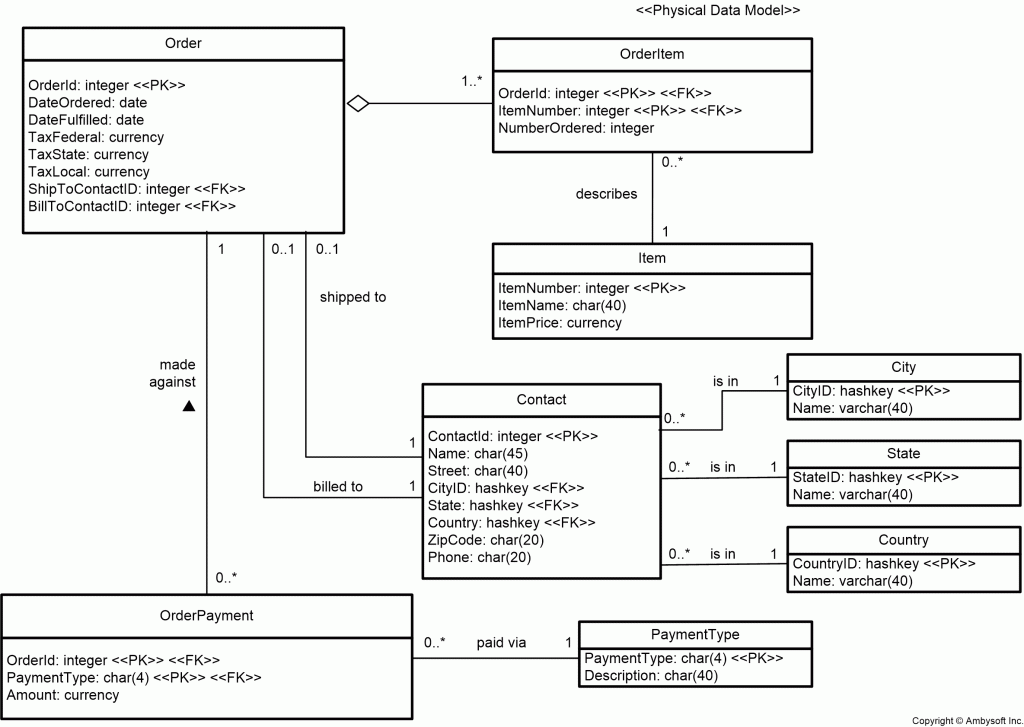
The data schema of Figure 4 can still be improved upon, at least from the point of view of data redundancy, by removing attributes that can be calculated/derived from other ones. In this case we could remove the SubtotalBeforeTax column within the Order3NF table and the TotalPriceExtended column of OrderItem3NF, as you see in Figure 5.
Figure 5. An Order Without Calculated Values (UML Notation).
3. Denormalization
From a purist point of view you want to normalize your data structures as much as possible, but from a practical point of view you will find that you need to ‘back out” of some of your normalizations for performance reasons. This is called “denormalization”. For example, with the data schema of Figure 1 all the data for a single order is stored in one row (assuming orders of up to nine order items), making it very easy to access. With the data schema of Figure 1 you could quickly determine the total amount of an order by reading the single row from the Order0NF table. To do so with the data schema of Figure 5 you would need to read data from a row in the Order table, data from all the rows from the OrderItem table for that order and data from the corresponding rows in the Item table for each order item. For this query, the data schema of Figure 1 very likely provides better performance.
4. Acknowledgements
I’d like to thank Jon Heggland and Nebojsa Trninic for their thoughtful review and feedback. They found several bugs which had gotten by both myself and my tech reviewers.