
Implementing Reports: Proven Strategies for Agile Teams
Reporting is a necessity within every organization and virtually within every business application. Your stakeholders will define some requirements that are best implemented as operational functionality, such as the definition and maintenance of customer information, and other requirements that are best implemented as reports. This article explores critical issues around implementing reports. How should you architect your database to support reporting? Should you build reports within your application or separately within another specialized reporting facility? Should you implement using object technology or with reporting tools? For our purposes, a report is the read-only output of information, potentially including both “raw” base data and calculated/summarized values. Reports can be rendered in a variety of manners – printed, displayed on a screen, or as a digital file. Reports can be created in batch or in real time. A customer invoice is a report, and so is a quarterly sales summary by division. In this article, I discuss:
- Database deployment architecture
- Reporting within your application
- Reporting outside your application
- Database design strategies
- Implementation strategies
- Challenges that make reporting hard
1. Database Deployment Architecture
Most business applications, particularly those that edit and update data contained in a relational database, require relatively normalized data. This basic manipulation of data is often referred to as the operational features of an application. Data normalization is a design process where the goal is to ensure that data is stored in one and one place only. This results in cohesive tables and a database schema that is very flexible. Because reports often require a wide range of data, resulting in the need to join many normalized tables, a highly normalized database can be difficult to report from. This problem is exacerbated when a report needs “crunch” a large amount of data. The implication is that you need a database architecture that supports the operational needs of your application as well as its reporting needs.
My experience is that because the operational needs of an application are best served by a highly normalized schema, and that because reporting needs are best served by a denormalized data schema, that you want to consider implementing two separate schemas. So far the focus of this book has been on the operational needs of an application, not on reporting, and therefore I have not discussed the idea of separate data schemas until now. Figure 1 depicts a logical database deployment architecture, depicting the idea that your application will read and update information from an operational database. Data from the operational database will be used to load data marts, if any, as well as your corporate data warehouse. An operational database supports online transaction processing and analytical reporting. A data mart is a department/application specific database used for reporting. A data warehouse is collection of subject-oriented databases where each unit of data is relevant to a given moment in time. Table 1 compares and contrasts these types of databases.
Figure 1. Separate operational and reporting databases.

Table 1. Comparing Database Types.
|
Operational Database |
Data Mart |
Data Warehouse |
|
|
|
Figure 1 depicts a logical architecture because a large organization is likely to have many physical operational databases, many physical data marts, and even several physical warehouses. A small company may have a single database that is used for all three purposes. Regardless of your physical implementation of this architecture, the basics still hold.
Inmon (2002) describes a process where the data from operational databases, including legacy databases, is denormalized and fed into the appropriate data marts. This data is loaded on a regular basis into the data marts, typically on a daily basis although periods of a few hours or even a few minutes is common. The data is also removed on a regular basis from the database to keep the data marts are a relatively stable size. Data is also loaded into your corporate data warehouse, although now this data will be highly denormalized and may need to be transformed to fit corporate data standards. The implication is that when an Agile data engineer evolves the data schema of your operational database, perhaps through database refactoring, they should always strive to ensure that the schema follows the enterprise data standards. This means they will need access to the standards, perhaps stored online in a meta data repository, and will need to work with the operations engineers to evolve the standards over time.
An advantage of separating operational databases from data marts and data warehouses is that it provides your team with the option to decouple your application from reporting-based data schemas. Although Figure 1 shows your application, via your encapsulation layer, accessing all three types of database you could choose to only interact directly with the operational database. This works when your application implements reports that are based only on data contained in the operational database. A better strategy is to externalize reports from your application and implement them via data mart or data warehouse-based reporting tools.
3. Reporting Within Your Application
Like any other functionality within your application, a report needs to be based on requirements. stakeholders should be working with application programmers and Agile data engineers to develop reports; the stakeholders provide the requirements and feedback on the work of the developers.
My implementation strategy for including reports in an application changes based on the development platform. When I’m building a fat-client application, perhaps building it with a Java Swing user interface or with Visual Basic, my preferred approach is to separate most if not all reports into their own application. In other words I build two applications, one that implements the operational logic and one that implements the reports. Sometimes I will invoke the reporting tool from the operational application so I can deploy a single, integrated application. Other times my stakeholders already have an existing reporting facility and they want the new reports to be added to it.
When I’m building a browser-based application I typically prefer to include reports in the operational application, although once again if my stakeholders want the reports to appear in a separate reporting application then that’s what I’ll do. My experience is that users of browser applications tend to want links to all related functionality within the application whereas users of fat client applications don’t mind having a separate application. I’ll implement a report as an HTML page that displays read-only information, or better it is implemented as an XML data structure than is then converted to HTML via XSLT (Extensible Stylesheet Language Transformation). Larry Greenfield presents a comprehensive list of reporting and query tools.
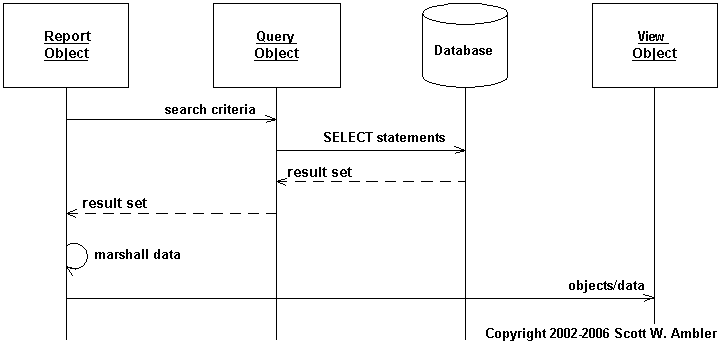
The logic to implement a report within your application code is fairly straightforward. You identify the selection rules for the information to appear in the report, for example “all employees with 5 or more years seniority that work in a Canadian subsidiary”. You then obtain the data using one of the strategies – brute force, query objects, or persistent search criteria – described in Effective Practices for Retrieving Objects from Relational Databases. This data is then converted into a format that your report generation strategy can work with. If you are not using a reporting framework then you will need to code the report yourself. A good strategy is the Report Objects design pattern (Brant & Yoder 2000) which implement a report with objects that obtain the data, known as query objects, and with objects that output the data, known as viewing objects. Figure 2 depicts a UML Sequence diagram that overviews this strategy. The report object collaborates with the query object to obtain the data, marshalling the results into the format required by the viewing object. The viewing object works with the marshaled results to produce the outputted report.
A design rule of thumb is that reports that appear as part of your operational application should be based on your operational data and should answer a “what is happening right now” type of question. Examples of this type of question include “what is the current inventory levels of Blink 182 CDs?”, “who is currently on call to answer Level 4 customer questions”, and “when is a customer’s order scheduled to be shipped?” When these two factors aren’t true you should consider building the report as part of an external reporting application.
4. Reporting Outside Your Application
A common strategy is to implement reports outside of your application, typically using a reporting facility design for exactly that purpose. This strategy is often referred to as business intelligence reporting. Figure 1 depicts this concept, showing how an ad-hoc reporting facility is often used against data marts whereas pre-defined reports are often run against data warehouses. Ad-hoc reporting is typically performed for the specific purposes of a small group of users where it is common that the users write the report(s) themselves. Pre-defined reports are typically developed by the IT department in response to user request, sometimes within the scope of an application and sometimes as a small initiative in its own right.
Why separate ad-hoc reports from pre-defined reports? As you saw in Table 1 data marts are designed to support flexible, unpredictable access to data whereas data warehouses are not designed this way. So, we don’t really need to separate the reports per se, just the databases. The implication is that your organization may already have a reporting strategy in place. This strategy will be reflected in your enterprise’s technical architecture and will encompass standard reporting tools, frameworks, and database technologies.
5. Database Design Strategies
What can you do design a database to be “performance friendly” to reports? In an ideal world you would like to have a perfectly normalized database, but it isn’t an ideal world. To support reports you often need to consider the following changes to your database design:
- Take advantage of database features. Each database implements joins, indices, SQL Select statement execution, and access paths in slightly different ways. All of these things influence the performance of your queries and thus your reports. This sort of basic knowledge is taught in database certification courses and I highly recommend that all Agile data engineers become certified on the database technologies that they work with. The disadvantage is that this approach helps to lock you into your database vendor because you come to rely on the unique features that they provide.
- Introduce aggregate tables. An aggregate table stores denormalized copies of data. For example, a CustomerOrders aggregate table would store summary totals of the orders for customers. There would be one row for each customer which records the number of orders placed, the number of shipments made, the grand total of the orders for that customer, and so on. The primary disadvantage is that you need to maintain the aggregate table.
- Remove unnecessary data. The smaller the amount of data to process, the faster your queries will run. By removing unnecessary data, either by archiving it or simply deleting it, you can improve the performance of your reports. The disadvantages are that you need to develop an archiving/deletion strategy and in the case of archiving you also need to develop a date recovery process to support retrieval of archived data.
- Caching. Caches, either of data or of objects, can dramatically improve your system performance by replacing relatively slow disk accesses with memory accesses. The disadvantages are the increased complexity and the increased chances of cross schema referential integrity problems introduced by caches.
- Partition a table. The goal is to take a large table, which results in poor performance, and reorganize it into several smaller tables. Tables can be partitioned vertically by storing different columns in each table as well as horizontally by storing collections of rows in different tables. Combinations are also possible. The primary disadvantages are that partitioning will complicate your mapping efforts (Chapter 11) and queries can become more complex because you need to work with several tables to support a single concept.
- Disallow real-time reports. Many organizations choose to only support batch reporting against databases to ensure that report queries do not interfere with operational applications, to ensure consistent performance levels within data marts and data warehouses, and to reserve update windows for those databases.
- Introduce indices. If a report needs to obtain data in a different order in which it is stored a common way to support this is to introduce an index that access the data in the required order. The disadvantage is that this slows down run-time performance due to the need to update the additional index.
There are other strategies that a good data engineer can implement to improve reporting performance, strategies that Larry Greenfield nicely summarizes.
6. Implementation Strategies
When implementing reports, and the data extracts to support them, there are several implementation strategies you should adopt:
- Follow report design guidelines. Your organization likely has report design guidelines, either formally documented ones which should be available from your enterprise administrators or informal ones which you will need to derive from existing reports. These design guidelines will describe mundane issues such as standard headers and footers to critical report layout conventions. Although it may seem boring, and your “creative juices” may motivate you to take your own approach, if you do in fact have a reasonable set of guidelines in place you should follow them. If all reports within your organization follow the same set of conventions they will be easier for your stakeholders to work with.
- Follow data design standards for extracted data. An important goal of your operations engineers is to maintain and support common data definitions and standards for your organization’s data. Although you should be applying these conventions when you are designing your database schema it is critical that extracted data does so because it will be shared throughout your organization.
- Add database views to support common reporting needs. Reporting data can be easier to extract with the addition of database views that perform common joins and projections within your database.
- Be prepared to work with imperfect data. There are many potential data quality problems, a problem that is exacerbated by the fact that the data in data marts and data warehouses come from many sources. Even if all of the data conforms to corporate standards there is very likely differences in the timeliness of data. Some extractions may run daily whereas others run hourly and some daily extractions may run several hours after others. These timing issues will impact your reports.
- Treat data extraction requests as new requirements. Agile software developers typically work from a prioritized stack of requirements . When a new requirement is proposed by a stakeholders the developers estimate it and ask the stakeholders to prioritize it, and if the stakeholders don’t like the estimate (What do you mean this will cost $50,000?) to rework and resubmit the requirement. The requirements are pulled off the stack and implemented in priority order. When an external database owner requests data elements from you, perhaps to fulfill the requirements of other teams, the request should be treated exactly like any other requirement – it should be estimated, prioritized, put on the stack, and eventually implemented.
- Investigate printing facilities and supplies. Your organization may have a printing framework, or perhaps a standard approach to printing, that your team can take advantage of. This is particularly true for any reports that are sent to your customers, such as invoices. The type of paper and envelopes will affect your report design. For example, does your organization have a standard envelope that requires you to print the address in a specific spot so that it lines up with the envelope window? Folding and envelope capacity are issues that may you need to be aware of as well. The point is that you need to work closely with your operations staff, people who are also considered to be stakeholders.
7. Challenges That Make Reporting Hard
Object technology doesn’t readily lend itself to reporting. Although you have several implementation strategies available to you none of them are ideal. A “pure” object-oriented approach would be solely based on object, but because many reports require information from thousands and sometimes millions of object the database access and marshalling alone can be performance inhibitive. Luckily “non-pure” solutions exist, such as developing report objects or integrating with reporting tools, but they will most likely require you to break your database encapsulation strategy.
When reports are printed physical issues are brought into your design. Simple things such as aligning your output with the fields on pre-printed forms can be tedious when you don’t have printer drivers specifically designed for those forms.
A more difficult issue to address is the fact that the owners of the data marts and your corporate data warehouse likely do not work in an agile manner, although this clearly does not need to be the case. You will need to find ways to work with them, perhaps a combination of helping them to become more agile and of learning to tolerate a little bit of bureaucracy. They may not be able to tolerate your team refactoring the layout of the data extract schema on a rapid basis, and may in fact require you to release on a much slower basis (quarterly instead of weekly). Furthermore they may not be able to respond quickly to your requests for schema changes within their databases. You’ll need to find ways to work together effectively, something that can be particularly hard if your team is the first one in your organization to take an agile approach to development.
Similarly your operations department, who likely control access to your corporate printing facilities, may not work in an agile manner. Once again you’ll need to find ways to work together.
Finally, don’t allow your team to drift into analysis paralysis because of some misguided goal to ascertain “one truth”.
8. What You Have Learned
This article focused on a basic but critical aspect of software-based systems – reporting. Your organization likely has a database architecture that takes reporting into consideration. This architecture may involve separate reporting databases, such as data marts and data warehouses, which you will need to export data too and then report from it. You learned that existing reporting tools and frameworks may exist for you to reuse on your initiative.
A fundamental decision that you need to make is whether reports are included as part of your application, if they are to be implemented in a separate reporting application/facility, or a combination thereof. When you are building them into your application you may choose to code them yourself or to use an integrated reporting tool.
My final word of advice is this: Don’t underestimate the difficulties implementing reports. The technical issues are straightforward to overcome but the people-oriented issues can prove to be your downfall. Work closely with all of your stakeholders, not just the business stakeholders.